Da jeg gik på aftenskole for at blive programmør, lærte jeg flere designmønstre: singleton, repository, factory, builder, decorator, osv. Designmønstre giver os en gennemprøvet løsning på eksisterende og tilbagevendende problemer. Hvad jeg ikke lærte, var, at der findes en lignende mekanisme på et højere niveau: softwarearkitekturmønstre. Det er mønstre for det overordnede layout af din applikation eller dine applikationer. De har alle fordele og ulemper. Og de tager alle fat på specifikke problemer.
Layered Pattern
Layered Pattern er nok et af de mest kendte softwarearkitekturmønstre. Mange udviklere bruger det, uden at de egentlig kender dets navn. Ideen er at dele din kode op i “lag”, hvor hvert lag har et bestemt ansvar og leverer en service til et højere lag.
Der er ikke et foruddefineret antal lag, men disse er dem, man ser oftest:
- Præsentations- eller UI-lag
- Anvendelseslag
- Business- eller domænelag
- Persistens- eller dataadgangslag
- Databaselag
Tanken er, at brugeren initierer et stykke kode i præsentationslaget ved at udføre en eller anden handling (f.eks.f.eks. ved at klikke på en knap). Præsentationslaget kalder derefter det underliggende lag, dvs. applikationslaget. Derefter går vi ind i forretningslaget, og til sidst gemmer persistenslaget alt i databasen. De højere lag er altså afhængige af og foretager kald til de lavere lag.

Du vil se variationer af dette, afhængigt af applikationernes kompleksitet. Nogle applikationer kan udelade applikationslaget, mens andre tilføjer et caching-lag. Det er endda muligt at slå to lag sammen til ét. F.eks. kombinerer ActiveRecord-mønstret forretningslaget og persistenslaget.
Lagansvar
Som nævnt har hvert lag sit eget ansvar. Præsentationslaget indeholder det grafiske design af applikationen samt eventuel kode til håndtering af brugerinteraktion. Du bør ikke tilføje logik, der ikke er specifik for brugergrænsefladen, i dette lag.
Det er i forretningslaget, at du lægger de modeller og den logik, der er specifik for det forretningsproblem, du forsøger at løse.
Applikationslaget ligger mellem præsentationslaget og forretningslaget. På den ene side giver det en abstraktion, så præsentationslaget ikke behøver at kende forretningslaget. I teorien kan du ændre teknologistakken i præsentationslaget uden at ændre noget andet i din applikation (f.eks. skifte fra WinForms til WPF). På den anden side giver applikationslaget et sted at placere visse koordineringslogikker, der ikke passer ind i forretnings- eller præsentationslaget.
Til sidst indeholder persistenslaget koden til at få adgang til databaselaget. Databaselaget er den underliggende databaseteknologi (f.eks. SQL Server, MongoDB). Persistenslaget er det sæt kode til at manipulere databasen: SQL-angivelser, forbindelsesoplysninger osv.
Fordele
- De fleste udviklere er bekendt med dette mønster.
- Det giver en nem måde at skrive en velorganiseret og testbar applikation på.
Ulemper
- Det har en tendens til at føre til monolitiske applikationer, som er svære at splitte op bagefter.
- Udviklerne finder ofte ud af at skrive en masse kode for at passere gennem de forskellige lag, uden at tilføje nogen værdi i disse lag. Hvis det eneste, du laver, er at skrive en simpel CRUD-applikation, er lagdelt mønster måske overkill for dig.
Ideal for
- Standard line-of-business-apps, der laver mere end blot CRUD-operationer
Microkernel
Mikrokernelmønsteret eller plug-in-mønsteret er nyttigt, når din applikation har et kernesæt af ansvarsområder og en samling af udskiftelige dele ved siden af. Mikrokernen vil levere indgangspunktet og det generelle flow i applikationen, uden at man egentlig ved, hvad de forskellige plug-ins laver.
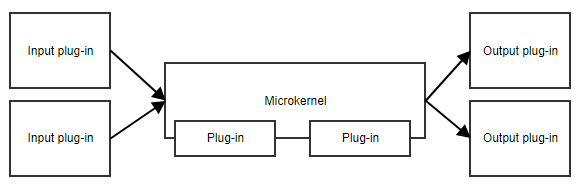
Et eksempel er en opgaveplanlægger. Mikrokernen kunne indeholde al logikken til planlægning og udløsning af opgaver, mens plug-ins indeholder specifikke opgaver. Så længe pluginsene overholder en foruddefineret API, kan mikrokernen udløse dem uden at skulle kende implementeringsdetaljerne.
Et andet eksempel er en arbejdsgang. Gennemførelsen af en arbejdsgang indeholder begreber som f.eks. rækkefølgen af de forskellige trin, evaluering af resultaterne af trinene, beslutning om, hvad det næste trin er, osv. Den specifikke implementering af trinene er mindre vigtig for workflowets kernekode.
Fordele
- Dette mønster giver stor fleksibilitet og udvidelsesmuligheder.
- Nogle implementeringer giver mulighed for at tilføje plug-ins, mens programmet kører.
- Mikrokernel og plug-ins kan udvikles af separate teams.
Ulemper
- Det kan være svært at afgøre, hvad der hører hjemme i mikrokernen, og hvad der ikke hører hjemme i mikrokernen.
- Den foruddefinerede API passer måske ikke godt til fremtidige plug-ins.
Ideal for
- Anvendelser, der tager data fra forskellige kilder, transformerer disse data og skriver dem til forskellige destinationer
- Arbejdsgangsprogrammer
- Task- og jobplanlægningsprogrammer
CQRS
CQRS er en forkortelse for Command and Query Responsibility Segregation (kommando- og forespørgselsansvarssegregation). Det centrale begreb i dette mønster er, at en applikation har læseoperationer og skriveoperationer, som skal være fuldstændig adskilt. Det betyder også, at den model, der anvendes til skriveoperationer (kommandoer), vil være forskellig fra læsemodellerne (forespørgsler). Desuden vil dataene blive lagret på forskellige steder. I en relationel database betyder det, at der vil være tabeller for kommandomodellen og tabeller for læsemodellen. Nogle implementeringer lagrer endda de forskellige modeller i helt forskellige databaser, f.eks. SQL Server for kommandomodellen og MongoDB for læsemodellen.
Dette mønster kombineres ofte med event sourcing, som vi vil dække nedenfor.
Hvordan fungerer det helt præcist? Når en bruger udfører en handling, sender programmet en kommando til kommandotjenesten. Kommandotjenesten henter alle de data, den har brug for, fra kommandodatabasen, foretager de nødvendige manipulationer og gemmer dem tilbage i databasen. Den underretter derefter læsetjenesten, så læsemodellen kan blive opdateret. Dette flow kan ses nedenfor.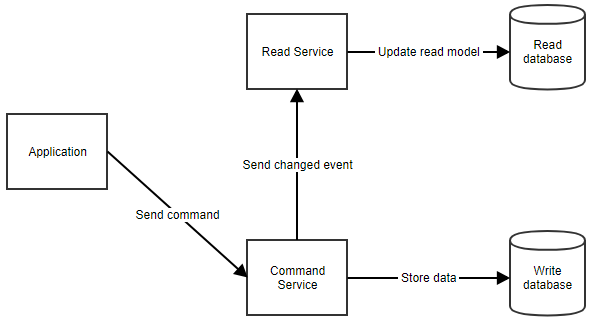
Når programmet skal vise data til brugeren, kan det hente den læste model ved at kalde læsetjenesten, som vist nedenfor.
Fordele
- Kommandomodeller kan fokusere på forretningslogik og validering, mens læsemodeller kan skræddersyes til specifikke scenarier.
- Du kan undgå komplekse forespørgsler (f.eks. joins i SQL), hvilket gør læsningerne mere performante.
Ulemper
- Det kan blive komplekst at holde kommando- og læsemodellerne synkroniseret.
Ideal for
- Anvendelser, der forventer en stor mængde læsninger
- Anvendelser med komplekse domæner
Event Sourcing
Som jeg nævnte ovenfor, går CQRS ofte hånd i hånd med event sourcing. Dette er et mønster, hvor du ikke gemmer den aktuelle tilstand af din model i databasen, men derimod de begivenheder, der er sket med modellen. Så når navnet på en kunde ændres, gemmer du ikke værdien i en “Name”-kolonne. Du vil gemme en “NameChanged”-begivenhed med den nye værdi (og muligvis også den gamle).
Når du skal hente en model, henter du alle dens gemte begivenheder og anvender dem igen på et nyt objekt. Vi kalder dette for at rehydrere et objekt.
En real-life-analogi af event sourcing er regnskab. Når du tilføjer en udgift, ændrer du ikke værdien af den samlede udgift. I regnskab tilføjes en ny linje med den operation, der skal udføres. Hvis der er sket en fejl, tilføjer man blot en ny linje. For at gøre dit liv lettere kunne du beregne totalen, hver gang du tilføjer en linje. Denne total kan betragtes som den aflæste model. Nedenstående eksempel skulle gøre det mere klart:

Du kan se, at vi har lavet en fejl, da vi tilføjede Faktura 201805. I stedet for at ændre linjen tilføjede vi to nye linjer: først en for at annullere den forkerte linje og derefter en ny og korrekt linje. Sådan fungerer event sourcing. Du fjerner aldrig begivenheder, fordi de unægteligt er sket i fortiden. For at rette situationer tilføjer vi nye hændelser.
Bemærk også, hvordan vi har en celle med den samlede værdi. Dette er simpelthen en sum af alle værdierne i de ovenstående celler. I Excel opdateres den automatisk, så man kan sige, at den synkroniseres med de andre celler. Det er den læste model, der giver en nem visning for brugeren.
Event sourcing kombineres ofte med CQRS, fordi rehydrering af et objekt kan have en indvirkning på ydelsen, især når der er mange begivenheder for instansen. En hurtig læsemodel kan forbedre applikationens responstid betydeligt.
Fordele
- Dette softwarearkitekturmønster kan give en revisionslog out of the box. Hver hændelse repræsenterer en manipulation af dataene på et bestemt tidspunkt.
Ulemper
- Det kræver en vis disciplin, fordi man ikke bare kan rette forkerte data med en simpel redigering i databasen.
- Det er ikke en triviel opgave at ændre strukturen af en hændelse. Hvis du f.eks. tilføjer en egenskab, indeholder databasen stadig hændelser uden disse data. Din kode skal håndtere disse manglende data nådigt.
Ideal til applikationer, der
- Har brug for at offentliggøre hændelser til eksterne systemer
- Vil blive bygget med CQRS
- Har komplekse domæner
- Har brug for en revisionslog over ændringer i dataene
Microservices
Når du skriver din applikation som et sæt af microservices, skriver du faktisk flere applikationer, der skal arbejde sammen. Hver mikroservice har sit eget særskilte ansvar, og teams kan udvikle dem uafhængigt af andre mikroservices. Den eneste afhængighed mellem dem er kommunikationen. Da microservices kommunikerer med hinanden, skal du sørge for, at meddelelser, der sendes mellem dem, forbliver bagudkompatible. Dette kræver en vis koordinering, især når forskellige teams er ansvarlige for forskellige microservices.
Et diagram kan forklare det.
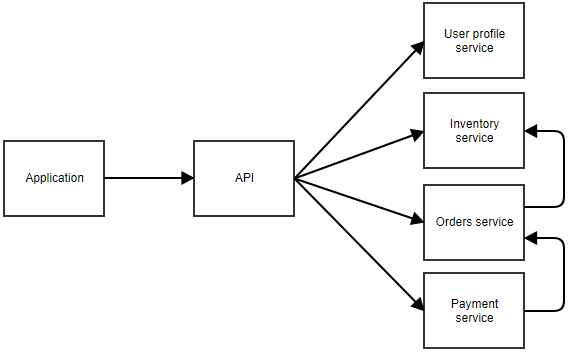 I ovenstående diagram kalder applikationen et centralt API, der videresender opkaldet til den korrekte microservice. I dette eksempel er der separate tjenester til brugerprofilen, lagerbeholdning, ordrer og betaling. Du kan forestille dig, at dette er en applikation, hvor brugeren kan bestille noget. De separate microservices kan også kalde hinanden. F.eks. kan betalingstjenesten underrette bestillingstjenesten, når en betaling lykkes. Bestillingstjenesten kan derefter kalde lagertjenesten for at justere lageret.
I ovenstående diagram kalder applikationen et centralt API, der videresender opkaldet til den korrekte microservice. I dette eksempel er der separate tjenester til brugerprofilen, lagerbeholdning, ordrer og betaling. Du kan forestille dig, at dette er en applikation, hvor brugeren kan bestille noget. De separate microservices kan også kalde hinanden. F.eks. kan betalingstjenesten underrette bestillingstjenesten, når en betaling lykkes. Bestillingstjenesten kan derefter kalde lagertjenesten for at justere lageret.
Der er ikke nogen klar regel for, hvor stor en mikroservice kan være. I det foregående eksempel kan brugerprofiltjenesten være ansvarlig for data som brugernavn og adgangskode for en bruger, men også hjemmeadresse, avatarbillede, favoritter osv. Det kunne også være en mulighed at opdele alle disse ansvarsområder i endnu mindre microservices.
Fordele
- Du kan skrive, vedligeholde og implementere hver microservice separat.
- En microservices-arkitektur skulle være nemmere at skalere at skalere, da du kun kan skalere de microservices, der har brug for at blive skaleret. Der er ikke behov for at skalere de mindre hyppigt anvendte dele af applikationen.
- Det er nemmere at omskrive dele af applikationen, fordi de er mindre og mindre koblet til andre dele.
Ulemper
- I modsætning til, hvad du måske forventer, er det faktisk nemmere at skrive en velstruktureret monolit til at begynde med og senere dele den op i mikrotjenester. Med microservices kommer der en masse ekstra bekymringer i spil: kommunikation, koordinering, bagudkompatibilitet, logning osv. Teams, der mangler de nødvendige færdigheder til at skrive en velstruktureret monolit, vil sandsynligvis have svært ved at skrive et godt sæt mikrotjenester.
- En enkelt handling fra en bruger kan passere gennem flere mikrotjenester. Der er flere fejlpunkter, og når noget går galt, kan det tage længere tid at lokalisere problemet.
Ideal for:
- Applikationer, hvor visse dele vil blive brugt intensivt og skal skaleres
- Tjenester, der leverer funktionalitet til flere andre applikationer
- Applikationer, der ville blive meget komplekse, hvis de blev kombineret i én monolit
- Applikationer, hvor der kan defineres klare afgrænsede kontekster
Kombinér
Jeg har forklaret flere softwarearkitekturmønstre, samt deres fordele og ulemper. Men der findes flere mønstre end dem, jeg har opstillet her. Det er heller ikke ualmindeligt at kombinere flere af disse mønstre. De er ikke altid gensidigt udelukkende. Du kan f.eks. have flere mikrotjenester og lade nogle af dem bruge lagdelt mønster, mens andre bruger CQRS og event sourcing.
Det vigtige at huske er, at der ikke findes én løsning, der virker overalt. Når vi stiller spørgsmålet om, hvilket mønster der skal bruges til en applikation, gælder det ældgamle svar stadig: “Det kommer an på”. Du bør afveje fordele og ulemper ved en løsning og træffe en velinformeret beslutning.