Als ich die Abendschule besuchte, um Programmierer zu werden, lernte ich mehrere Design Patterns: Singleton, Repository, Factory, Builder, Decorator, etc. Entwurfsmuster geben uns eine bewährte Lösung für bestehende und wiederkehrende Probleme. Was ich nicht gelernt habe, ist, dass ein ähnlicher Mechanismus auf einer höheren Ebene existiert: Softwarearchitekturmuster. Dabei handelt es sich um Muster für das Gesamtlayout Ihrer Anwendung oder Anwendungen. Sie haben alle Vor- und Nachteile. Und sie behandeln alle spezifische Probleme.
Schichtmuster
Das Schichtmuster ist wahrscheinlich eines der bekanntesten Softwarearchitekturmuster. Viele Entwickler verwenden es, ohne seinen Namen wirklich zu kennen. Die Idee ist, den Code in „Schichten“ aufzuteilen, wobei jede Schicht eine bestimmte Verantwortung hat und einen Dienst für eine höhere Schicht bereitstellt.
Es gibt keine vordefinierte Anzahl von Schichten, aber diese sind die, die man am häufigsten sieht:
- Präsentations- oder UI-Schicht
- Anwendungsschicht
- Geschäfts- oder Domänenschicht
- Persistenz- oder Datenzugriffsschicht
- Datenbankschicht
Die Idee ist, dass der Benutzer ein Stück Code in der Präsentationsschicht initiiert, indem er eine Aktion ausführt (z.z. B. Klicken auf eine Schaltfläche). Die Präsentationsschicht ruft dann die darunter liegende Schicht, d. h. die Anwendungsschicht, auf. Dann geht es in die Geschäftsschicht und schließlich speichert die Persistenzschicht alles in der Datenbank. Höhere Schichten sind also von den unteren Schichten abhängig und rufen diese auf.

Abhängig von der Komplexität der Anwendungen werden Sie Variationen dieser Vorgehensweise sehen. Einige Anwendungen können die Anwendungsschicht weglassen, während andere eine Caching-Schicht hinzufügen. Es ist sogar möglich, zwei Schichten zu einer zu verschmelzen. Das ActiveRecord-Muster kombiniert beispielsweise die Geschäfts- und die Persistenzschicht.
Schichtverantwortung
Wie bereits erwähnt, hat jede Schicht ihre eigene Verantwortung. Die Präsentationsschicht enthält das grafische Design der Anwendung sowie jeglichen Code zur Handhabung der Benutzerinteraktion. In diese Schicht sollte keine Logik eingefügt werden, die nicht spezifisch für die Benutzeroberfläche ist.
Die Geschäftsschicht enthält die Modelle und die Logik, die spezifisch für das zu lösende Geschäftsproblem ist.
Die Anwendungsschicht befindet sich zwischen der Präsentationsschicht und der Geschäftsschicht. Einerseits bietet sie eine Abstraktion, so dass die Präsentationsschicht die Geschäftsschicht nicht kennen muss. Theoretisch könnten Sie den Technologiestack der Präsentationsschicht ändern, ohne etwas anderes in Ihrer Anwendung zu ändern (z. B. Wechsel von WinForms zu WPF). Andererseits bietet die Anwendungsschicht einen Platz für bestimmte Koordinationslogik, die nicht in die Geschäfts- oder Präsentationsschicht passt.
Schließlich enthält die Persistenzschicht den Code für den Zugriff auf die Datenbankschicht. Die Datenbankschicht ist die zugrunde liegende Datenbanktechnologie (z.B. SQL Server, MongoDB). Die Persistenzschicht besteht aus dem Code zur Bearbeitung der Datenbank: SQL-Anweisungen, Verbindungsdetails usw.
Vorteile
- Die meisten Entwickler sind mit diesem Muster vertraut.
- Es bietet eine einfache Möglichkeit, eine gut organisierte und testbare Anwendung zu schreiben.
Nachteile
- Es neigt dazu, zu monolithischen Anwendungen zu führen, die sich später nur schwer aufteilen lassen.
- Entwickler schreiben oft eine Menge Code, um die verschiedenen Schichten zu durchlaufen, ohne in diesen Schichten einen Mehrwert zu schaffen. Wenn Sie nur eine einfache CRUD-Anwendung schreiben, könnte das Schichtenmuster für Sie ein Overkill sein.
Ideal für
- Standardanwendungen, die mehr als nur CRUD-Operationen ausführen
Microkernel
Das Microkernel-Muster oder Plug-in-Muster ist nützlich, wenn Ihre Anwendung einen Kernsatz von Verantwortlichkeiten und eine Sammlung von austauschbaren Teilen an der Seite hat. Der Mikrokernel stellt den Einstiegspunkt und den allgemeinen Ablauf der Anwendung bereit, ohne wirklich zu wissen, was die verschiedenen Plug-ins tun.
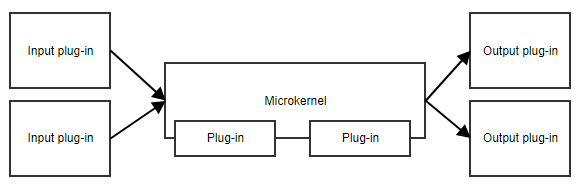
Ein Beispiel ist ein Aufgabenplaner. Der Mikrokernel könnte die gesamte Logik für das Planen und Auslösen von Aufgaben enthalten, während die Plug-ins spezifische Aufgaben enthalten. Solange sich die Plug-ins an eine vordefinierte API halten, kann der Mikrokernel sie auslösen, ohne die Implementierungsdetails kennen zu müssen.
Ein weiteres Beispiel ist ein Workflow. Die Implementierung eines Workflows enthält Konzepte wie die Reihenfolge der verschiedenen Schritte, die Auswertung der Ergebnisse von Schritten, die Entscheidung über den nächsten Schritt usw. Die spezifische Implementierung der Schritte ist für den Kerncode des Workflows weniger wichtig.
Vorteile
- Dieses Muster bietet große Flexibilität und Erweiterbarkeit.
- Einige Implementierungen ermöglichen das Hinzufügen von Plug-ins, während die Anwendung läuft.
- Microkernel und Plug-ins können von getrennten Teams entwickelt werden.
Nachteile
- Es kann schwierig sein zu entscheiden, was in den Microkernel gehört und was nicht.
- Die vordefinierte API könnte für zukünftige Plug-ins nicht geeignet sein.
Ideal für
- Anwendungen, die Daten aus verschiedenen Quellen übernehmen, umwandeln und an verschiedene Ziele schreiben
- Workflow-Anwendungen
- Task- und Job Scheduling-Anwendungen
CQRS
CQRS ist eine Abkürzung für Command and Query Responsibility Segregation. Das zentrale Konzept dieses Musters ist, dass eine Anwendung Lese- und Schreiboperationen hat, die vollständig getrennt sein müssen. Das bedeutet auch, dass das Modell für Schreiboperationen (Befehle) sich von den Lesemodellen (Abfragen) unterscheidet. Außerdem werden die Daten an unterschiedlichen Orten gespeichert. In einer relationalen Datenbank bedeutet dies, dass es Tabellen für das Befehlsmodell und Tabellen für das Lesemodell gibt. Einige Implementierungen speichern die verschiedenen Modelle sogar in völlig unterschiedlichen Datenbanken, z. B. SQL Server für das Befehlsmodell und MongoDB für das Lesemodell.
Dieses Muster wird häufig mit Event Sourcing kombiniert, auf das wir weiter unten eingehen werden.
Wie funktioniert das genau? Wenn ein Benutzer eine Aktion ausführt, sendet die Anwendung einen Befehl an den Befehlsdienst. Der Befehlsdienst ruft alle benötigten Daten aus der Befehlsdatenbank ab, führt die notwendigen Manipulationen durch und speichert sie wieder in der Datenbank. Anschließend benachrichtigt er den Lesedienst, damit das Lesemodell aktualisiert werden kann. Dieser Ablauf ist unten zu sehen.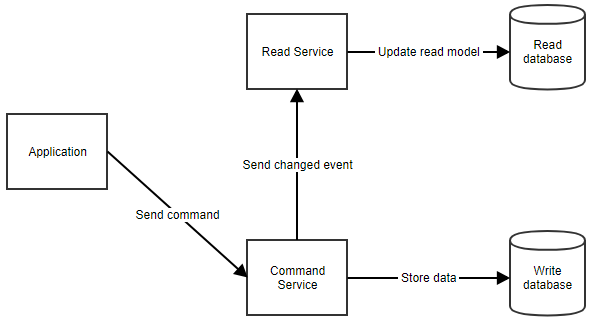
Wenn die Anwendung dem Benutzer Daten zeigen muss, kann sie das Lesemodell abrufen, indem sie den Lesedienst aufruft, wie unten gezeigt.
Vorteile
- Befehlsmodelle können sich auf Geschäftslogik und Validierung konzentrieren, während Lesemodelle auf spezifische Szenarien zugeschnitten werden können.
- Sie können komplexe Abfragen vermeiden (z.B.
Nachteile
- Die Synchronisierung der Befehls- und Lesemodelle kann komplex werden.
Ideal für
- Anwendungen, die eine hohe Anzahl von Lesevorgängen erwarten
- Anwendungen mit komplexen Domänen
Event Sourcing
Wie ich bereits erwähnt habe, geht CQRS oft Hand in Hand mit Event Sourcing. Dabei handelt es sich um ein Muster, bei dem nicht der aktuelle Zustand des Modells in der Datenbank gespeichert wird, sondern die Ereignisse, die mit dem Modell passiert sind. Wenn sich also der Name eines Kunden ändert, speichern Sie den Wert nicht in einer Spalte „Name“. Sie werden ein „NameChanged“-Ereignis mit dem neuen Wert (und möglicherweise auch dem alten) speichern.
Wenn Sie ein Modell abrufen müssen, rufen Sie alle gespeicherten Ereignisse ab und wenden sie auf ein neues Objekt an. Wir nennen dies die Rehydrierung eines Objekts.
Eine Analogie zur Ereignisbeschaffung im wirklichen Leben ist die Buchhaltung. Wenn Sie eine Ausgabe hinzufügen, ändern Sie nicht den Wert der Gesamtsumme. In der Buchhaltung wird eine neue Zeile mit dem auszuführenden Vorgang hinzugefügt. Wenn ein Fehler gemacht wurde, fügen Sie einfach eine neue Zeile hinzu. Um Ihnen das Leben zu erleichtern, könnten Sie jedes Mal, wenn Sie eine Zeile hinzufügen, die Gesamtsumme berechnen. Diese Summe kann als Lesemodell betrachtet werden. Das folgende Beispiel soll dies verdeutlichen.

Sie sehen, dass uns beim Hinzufügen der Rechnung 201805 ein Fehler unterlaufen ist. Anstatt die Zeile zu ändern, haben wir zwei neue Zeilen hinzugefügt: zuerst eine, um die falsche Zeile zu stornieren, dann eine neue und richtige Zeile. So funktioniert die Ereignisbeschaffung. Man entfernt niemals Ereignisse, weil sie unbestreitbar in der Vergangenheit stattgefunden haben. Um Situationen zu korrigieren, fügen wir neue Ereignisse hinzu.
Beachten Sie auch, dass wir eine Zelle mit dem Gesamtwert haben. Dies ist einfach die Summe aller Werte in den Zellen oben. In Excel wird sie automatisch aktualisiert, man könnte also sagen, dass sie mit den anderen Zellen synchronisiert wird. Dies ist das Lesemodell, das dem Benutzer eine einfache Ansicht bietet.
Event Sourcing wird oft mit CQRS kombiniert, da die Rehydrierung eines Objekts Auswirkungen auf die Leistung haben kann, insbesondere wenn es viele Ereignisse für die Instanz gibt. Ein schnelles Lesemodell kann die Antwortzeit der Anwendung erheblich verbessern.
Vorteile
- Dieses Softwarearchitekturmuster kann ein Audit-Protokoll von Anfang an bereitstellen. Jedes Ereignis stellt eine Manipulation der Daten zu einem bestimmten Zeitpunkt dar.
Nachteile
- Es erfordert ein gewisses Maß an Disziplin, da man falsche Daten nicht einfach durch eine einfache Bearbeitung in der Datenbank korrigieren kann.
- Es ist keine triviale Aufgabe, die Struktur eines Ereignisses zu ändern. Wenn Sie zum Beispiel eine Eigenschaft hinzufügen, enthält die Datenbank immer noch Ereignisse ohne diese Daten. Ihr Code muss mit diesen fehlenden Daten gnädig umgehen.
Ideal für Anwendungen, die
- Ereignisse in externen Systemen veröffentlichen müssen
- Mit CQRS erstellt werden
- Komplexe Domänen
- Brauchen ein Audit-Protokoll der Datenänderungen
Microservices
Wenn Sie Ihre Anwendung als eine Reihe von Microservices schreiben, schreiben Sie eigentlich mehrere Anwendungen, die zusammenarbeiten werden. Jeder Microservice hat seine eigene Verantwortung und Teams können sie unabhängig von anderen Microservices entwickeln. Die einzige Abhängigkeit zwischen ihnen besteht in der Kommunikation. Da Microservices miteinander kommunizieren, müssen Sie sicherstellen, dass die zwischen ihnen gesendeten Nachrichten abwärtskompatibel bleiben. Dies erfordert ein gewisses Maß an Koordination, insbesondere wenn verschiedene Teams für unterschiedliche Microservices zuständig sind.
Ein Diagramm kann dies verdeutlichen.
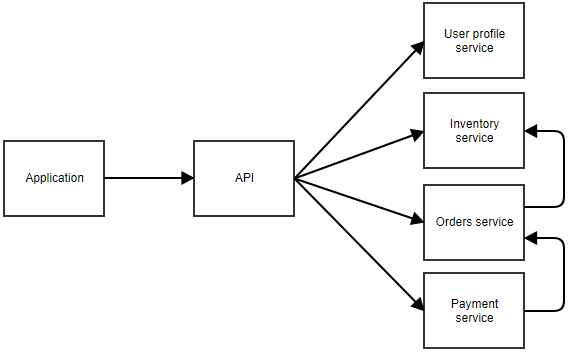 In dem obigen Diagramm ruft die Anwendung eine zentrale API auf, die den Aufruf an den richtigen Microservice weiterleitet. In diesem Beispiel gibt es separate Dienste für das Benutzerprofil, den Bestand, die Bestellungen und die Bezahlung. Sie können sich vorstellen, dass es sich um eine Anwendung handelt, in der der Benutzer etwas bestellen kann. Die einzelnen Microservices können sich auch gegenseitig aufrufen. Zum Beispiel kann der Zahlungsdienst den Bestelldienst benachrichtigen, wenn eine Zahlung erfolgreich war. Der Bestelldienst könnte dann den Bestandsdienst aufrufen, um den Bestand anzupassen.
In dem obigen Diagramm ruft die Anwendung eine zentrale API auf, die den Aufruf an den richtigen Microservice weiterleitet. In diesem Beispiel gibt es separate Dienste für das Benutzerprofil, den Bestand, die Bestellungen und die Bezahlung. Sie können sich vorstellen, dass es sich um eine Anwendung handelt, in der der Benutzer etwas bestellen kann. Die einzelnen Microservices können sich auch gegenseitig aufrufen. Zum Beispiel kann der Zahlungsdienst den Bestelldienst benachrichtigen, wenn eine Zahlung erfolgreich war. Der Bestelldienst könnte dann den Bestandsdienst aufrufen, um den Bestand anzupassen.
Es gibt keine klare Regel, wie groß ein Microservice sein darf. Im vorherigen Beispiel könnte der Benutzerprofildienst für Daten wie den Benutzernamen und das Passwort eines Benutzers zuständig sein, aber auch für die Heimatadresse, das Avatarbild, die Favoriten usw. Es könnte auch eine Option sein, all diese Verantwortlichkeiten in noch kleinere Microservices aufzuteilen.
Vorteile
- Sie können jeden Microservice separat schreiben, warten und bereitstellen.
- Eine Microservices-Architektur sollte einfacher zu skalieren sein, da Sie nur die Microservices skalieren können, die skaliert werden müssen. Es besteht keine Notwendigkeit, die weniger häufig genutzten Teile der Anwendung zu skalieren.
- Es ist einfacher, Teile der Anwendung neu zu schreiben, da sie kleiner und weniger an andere Teile gekoppelt sind.
Nachteile
- Im Gegensatz zu dem, was Sie vielleicht erwarten, ist es tatsächlich einfacher, zunächst einen gut strukturierten Monolithen zu schreiben und ihn später in Microservices aufzuteilen. Bei Microservices kommen viele zusätzliche Aspekte ins Spiel: Kommunikation, Koordination, Rückwärtskompatibilität, Protokollierung usw. Teams, die nicht über die notwendigen Fähigkeiten verfügen, um einen gut strukturierten Monolithen zu schreiben, werden es wahrscheinlich schwer haben, einen guten Satz von Microservices zu schreiben.
- Eine einzelne Aktion eines Benutzers kann mehrere Microservices durchlaufen. Es gibt mehr Fehlerquellen, und wenn etwas schief geht, kann es länger dauern, das Problem zu lokalisieren.
Ideal für:
- Anwendungen, bei denen bestimmte Teile intensiv genutzt werden und skaliert werden müssen
- Dienste, die Funktionen für mehrere andere Anwendungen bereitstellen
- Anwendungen, die sehr komplex werden würden, wenn man sie zu einem Monolithen zusammenfassen würde
- Anwendungen, bei denen klar abgegrenzte Kontexte definiert werden können
Kombinieren
Ich habe mehrere Software-Architekturmuster erläutert, sowie deren Vor- und Nachteile. Aber es gibt noch mehr Muster als die, die ich hier vorgestellt habe. Es ist auch nicht unüblich, mehrere dieser Muster zu kombinieren. Sie schließen sich nicht immer gegenseitig aus. Sie könnten zum Beispiel mehrere Microservices haben und einige von ihnen das Layered Pattern verwenden, während andere CQRS und Event Sourcing nutzen.
Das Wichtigste ist, dass es nicht die eine Lösung gibt, die überall funktioniert. Auf die Frage, welches Muster für eine Anwendung verwendet werden soll, gilt immer noch die uralte Antwort: „Es kommt darauf an.“ Sie sollten die Vor- und Nachteile einer Lösung abwägen und eine fundierte Entscheidung treffen.