- Existen muchos métodos para probar si una variable tiene una distribución normal. En este artículo, descubrirá cuál debe utilizar.
- 1.1. Introducción Introducción
- 1.2. Interpretación
- 1.3. Implementación
- 1.4. Conclusión
- 2.1. Introducción
- 2.2 Interpretación
- 2.3. Implementación
- 2.4. Conclusión
- 3.1. Introducción
- 3.2. Interpretación
- 3.3. Implementación
- 3.4. Conclusión
- Prueba de Kolmogorov Smirnov
- 4.2. Interpretación
- 4.3. Implementación
- 4.4. Conclusión
- Prueba de Lilliefors
- 5.2. Interpretación
- 5.3. Implementación
- 5.4. Conclusión
- Prueba de Shapiro Wilk
- 6.2. Interpretación Interpretación
- 6.3. Implementación
- 6.4. Conclusión
- Conclusión – ¡qué enfoque utilizar!
Existen muchos métodos para probar si una variable tiene una distribución normal. En este artículo, descubrirá cuál debe utilizar.
1.1. Introducción Introducción
El primer método que casi todo el mundo conoce es el histograma. El histograma es una visualización de datos que muestra la distribución de una variable. Nos da la frecuencia de aparición por valor en el conjunto de datos, que es de lo que tratan las distribuciones.
El histograma es una gran manera de visualizar rápidamente la distribución de una sola variable.
1.2. Interpretación
En la imagen siguiente, dos histogramas muestran una distribución normal y una distribución no normal.
- A la izquierda, hay muy poca desviación de la distribución de la muestra (en gris) respecto a la distribución teórica de la campana (línea roja).
- A la derecha, vemos una forma bastante diferente en el histograma, lo que nos indica directamente que no se trata de una distribución normal.

1.3. Implementación
Un histograma se puede crear fácilmente en python de la siguiente manera:
1.4. Conclusión
El histograma es una gran manera de visualizar rápidamente la distribución de una sola variable.
2.1. Introducción
La gráfica de caja es otra técnica de visualización que puede utilizarse para detectar muestras no normales. El Box Plot traza el resumen de 5 números de una variable: mínimo, primer cuartil, mediana, tercer cuartil y máximo.
El boxplot es una gran manera de visualizar las distribuciones de múltiples variables al mismo tiempo.
2.2 Interpretación
El boxplot es una gran técnica de visualización porque permite trazar muchos boxplots uno al lado del otro. Tener esta visión general muy rápida de las variables nos da una idea de la distribución y, como «bonus», obtenemos el resumen completo de 5 números que nos ayudará en el análisis posterior.
Debe fijarse en dos cosas:
- ¿Es la distribución simétrica (como lo es la distribución Normal)?
- ¿Corresponde la anchura (opuesta a la puntualidad) a la anchura de la distribución normal? Esto es difícil de ver en un diagrama de caja.

2.3. Implementación
Un boxplot puede implementarse fácilmente en python de la siguiente manera:
2.4. Conclusión
El boxplot es una gran manera de visualizar distribuciones de múltiples variables al mismo tiempo, pero una desviación en la anchura/puntualidad es difícil de identificar usando box plots.
3.1. Introducción
Con los gráficos QQ estamos empezando a entrar en lo más serio, ya que esto requiere un poco más de comprensión que los métodos descritos anteriormente.
El QQ Plot significa Quantile vs Quantile Plot, que es exactamente lo que hace: trazar cuantiles teóricos contra los cuantiles reales de nuestra variable.
El QQ Plot nos permite ver la desviación de una distribución normal mucho mejor que en un Histograma o Box Plot.
3.2. Interpretación
Si nuestra variable sigue una distribución normal, los cuantiles de nuestra variable deben coincidir perfectamente con los cuantiles normales «teóricos»: una línea recta en el QQ Plot nos indica que tenemos una distribución normal.
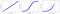
Como se ve en la imagen, los puntos de un QQ Plot normal siguen una línea recta, mientras que otras distribuciones se desvían mucho.
- La distribución uniforme tiene demasiadas observaciones en ambos extremos (valores muy altos y muy bajos).
- La distribución exponencial tiene demasiadas observaciones en los valores más bajos, pero muy pocas en los valores más altos.
En la práctica, a menudo vemos algo menos pronunciado pero de forma similar. La representación excesiva o insuficiente en la cola debería provocar dudas sobre la normalidad, en cuyo caso debería utilizar una de las pruebas de hipótesis descritas a continuación.
3.3. Implementación
La implementación de un QQ Plot puede hacerse utilizando la api de statsmodels en python como sigue:
3.4. Conclusión
El QQ Plot nos permite ver la desviación de una distribución normal mucho mejor que en un Histograma o gráfico de cajas.
Prueba de Kolmogorov Smirnov
Si el QQ Plot y otras técnicas de visualización no son concluyentes, la inferencia estadística (Prueba de Hipótesis) puede dar una respuesta más objetiva a si nuestra variable se desvía significativamente de una distribución normal.
Si tienes dudas sobre cómo y cuándo utilizar las pruebas de hipótesis, aquí tienes un artículo que da una explicación intuitiva a las pruebas de hipótesis.
La prueba de Kolmogorov Smirnov calcula las distancias entre la distribución empírica y la distribución teórica y define el estadístico de la prueba como la suma del conjunto de esas distancias.
La ventaja de esto es que el mismo enfoque se puede utilizar para comparar cualquier distribución, no necesariamente la distribución normal solamente.
La prueba KS es bien conocida pero no tiene mucha potencia. Se puede utilizar para otra distribución que no sea la normal.
4.2. Interpretación
El estadístico de prueba de la prueba KS es el estadístico de Kolmogorov Smirnov, que sigue una distribución de Kolmogorov si la hipótesis nula es verdadera.
Si los datos observados siguen perfectamente una distribución normal, el valor del estadístico KS será 0. El valor P se utiliza para decidir si la diferencia es lo suficientemente grande como para rechazar la hipótesis nula:
- Si el valor P de la prueba KS es mayor que 0,05, asumimos una distribución normal
- Si el valor P de la prueba KS es menor que 0,05, no asumimos una distribución normal
4.3. Implementación
La prueba KS en Python usando Scipy se puede implementar de la siguiente manera. Devuelve el estadístico KS y su valor P.
4.4. Conclusión
La prueba KS es bien conocida pero no tiene mucha potencia. Esto significa que es necesario un gran número de observaciones para rechazar la hipótesis nula. También es sensible a los valores atípicos. Por otro lado, puede utilizarse para otros tipos de distribuciones.
Prueba de Lilliefors
La prueba de Lilliefors se basa en gran medida en la prueba KS. La diferencia es que en la prueba de Lilliefors se acepta que la media y la varianza de la distribución de la población sean estimadas en lugar de ser preespecificadas por el usuario.
Debido a esto, la prueba de Lilliefors utiliza la distribución de Lilliefors en lugar de la distribución de Kolmogorov.
Desgraciadamente para Lilliefors, su potencia sigue siendo inferior a la de la prueba de Shapiro Wilk.
5.2. Interpretación
- Si el valor P de la prueba de Lilliefors es mayor que 0,05, asumimos una distribución normal
- Si el valor P de la prueba de Lilliefors es menor que 0,05, no asumimos una distribución normal
5.3. Implementación
La implementación de la prueba de Lilliefors en statsmodels devolverá el valor del estadístico de la prueba de Lilliefors y el valor P de la siguiente manera.
Atención: en la implementación de statsmodels, los valores P inferiores a 0.001 se reportan como 0,001 y los valores P superiores a 0,2 se reportan como 0,2.
5.4. Conclusión
Aunque Lilliefors es una mejora de la prueba KS, su potencia sigue siendo inferior a la de la prueba de Shapiro Wilk.
Prueba de Shapiro Wilk
La prueba de Shapiro Wilk es la más potente cuando se comprueba una distribución normal. Se ha desarrollado específicamente para la distribución normal y no se puede utilizar para contrastar con otras distribuciones como, por ejemplo, la prueba KS.
La prueba de Shapiro Wilk es la más potente a la hora de contrastar una distribución normal.
6.2. Interpretación Interpretación
- Si el valor P de la prueba de Shapiro Wilk es mayor que 0,05, asumimos una distribución normal
- Si el valor P de la prueba de Shapiro Wilk es menor que 0,05, no asumimos una distribución normal
6.3. Implementación
La prueba de Shapiro Wilk se puede implementar de la siguiente manera. Devolverá el estadístico de prueba llamado W y el valor P.
Atención: para N > 5000 el estadístico de prueba W es exacto pero el valor p puede no serlo.
6.4. Conclusión
La prueba de Shapiro Wilk es la prueba más potente cuando se comprueba una distribución normal. Definitivamente debe utilizar esta prueba.
Conclusión – ¡qué enfoque utilizar!
Para una identificación rápida y visual de una distribución normal, utilice un gráfico QQ si sólo tiene una variable que mirar y un gráfico de cajas si tiene muchas. Utilice un histograma si necesita presentar sus resultados a un público no estadístico.
Como prueba estadística para confirmar su hipótesis, utilice la prueba de Shapiro Wilk. Es la prueba más potente, que debería ser el argumento decisivo.
Cuando se realizan pruebas contra otras distribuciones, no se puede utilizar Shapiro Wilk y se debe utilizar, por ejemplo, la prueba de Anderson-Darling o la prueba KS.