Cuando asistía a la escuela nocturna para convertirme en programador, aprendí varios patrones de diseño: singleton, repositorio, fábrica, constructor, decorador, etc. Los patrones de diseño nos dan una solución probada a problemas existentes y recurrentes. Lo que no aprendí es que existe un mecanismo similar a un nivel superior: los patrones de arquitectura de software. Se trata de patrones para el diseño general de tu aplicación o aplicaciones. Todos tienen ventajas y desventajas. Y todos abordan cuestiones específicas.
Patrón de capas
El patrón de capas es probablemente uno de los patrones de arquitectura de software más conocidos. Muchos desarrolladores lo utilizan, sin saber realmente su nombre. La idea es dividir tu código en «capas», donde cada capa tiene una determinada responsabilidad y proporciona un servicio a una capa superior.
No hay un número predefinido de capas, pero estas son las que se ven más a menudo:
- Capa de presentación o UI
- Capa de aplicación
- Capa de negocio o dominio
- Capa de persistencia o acceso a datos
- Capa de base de datos
La idea es que el usuario inicie una pieza de código en la capa de presentación realizando alguna acción (e.por ejemplo, haciendo clic en un botón). La capa de presentación entonces llama a la capa subyacente, es decir, la capa de aplicación. Luego pasamos a la capa de negocio y, finalmente, la capa de persistencia almacena todo en la base de datos. Así que las capas superiores dependen y hacen llamadas a las capas inferiores.

Verás variaciones de esto, dependiendo de la complejidad de las aplicaciones. Algunas aplicaciones pueden omitir la capa de aplicación, mientras que otras añaden una capa de caché. Incluso es posible fusionar dos capas en una. Por ejemplo, el patrón ActiveRecord combina las capas de negocio y persistencia.
Responsabilidad de las capas
Como se ha mencionado, cada capa tiene su propia responsabilidad. La capa de presentación contiene el diseño gráfico de la aplicación, así como cualquier código para manejar la interacción con el usuario. En esta capa no se debe añadir lógica que no sea específica de la interfaz de usuario.
La capa de negocio es donde se colocan los modelos y la lógica que es específica del problema de negocio que se intenta resolver.
La capa de aplicación se sitúa entre la capa de presentación y la capa de negocio. Por un lado, proporciona una abstracción para que la capa de presentación no necesite conocer la capa de negocio. En teoría, podrías cambiar la pila tecnológica de la capa de presentación sin cambiar nada más en tu aplicación (por ejemplo, cambiar de WinForms a WPF). Por otro lado, la capa de aplicación proporciona un lugar para poner cierta lógica de coordinación que no encaja en la capa de negocio o de presentación.
Por último, la capa de persistencia contiene el código para acceder a la capa de base de datos. La capa de base de datos es la tecnología de base de datos subyacente (por ejemplo, SQL Server, MongoDB). La capa de persistencia es el conjunto de código para manipular la base de datos: sentencias SQL, detalles de conexión, etc.
Ventajas
- La mayoría de los desarrolladores están familiarizados con este patrón.
- Proporciona una forma fácil de escribir una aplicación bien organizada y comprobable.
Desventajas
- Tiende a conducir a aplicaciones monolíticas que son difíciles de dividir después.
- Los desarrolladores a menudo se encuentran escribiendo un montón de código para pasar por las diferentes capas, sin añadir ningún valor en estas capas. Si todo lo que estás haciendo es escribir una simple aplicación CRUD, el patrón de capas podría ser excesivo para ti.
Ideal para
- Aplicaciones de línea de negocio estándar que hacen algo más que operaciones CRUD
Microkernel
El patrón microkernel, o patrón plug-in, es útil cuando tu aplicación tiene un conjunto de responsabilidades principales y una colección de partes intercambiables al margen. El microkernel proporcionará el punto de entrada y el flujo general de la aplicación, sin saber realmente lo que los diferentes plug-ins están haciendo.
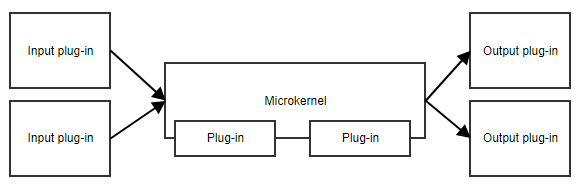
Un ejemplo es un programador de tareas. El micronúcleo podría contener toda la lógica para programar y desencadenar tareas, mientras que los plug-ins contienen tareas específicas. Mientras los complementos se adhieran a una API predefinida, el micronúcleo puede activarlos sin necesidad de conocer los detalles de la implementación.
Otro ejemplo es un flujo de trabajo. La implementación de un flujo de trabajo contiene conceptos como el orden de los diferentes pasos, la evaluación de los resultados de los pasos, la decisión de cuál es el siguiente paso, etc. La implementación específica de los pasos es menos importante para el código central del flujo de trabajo.
Ventajas
- Este patrón proporciona una gran flexibilidad y extensibilidad.
- Algunas implementaciones permiten añadir complementos mientras la aplicación se está ejecutando.
- El micronúcleo y los complementos pueden ser desarrollados por equipos separados.
Desventajas
- Puede ser difícil decidir qué pertenece al micronúcleo y qué no.
- La API predefinida podría no ser un buen ajuste para futuros plug-ins.
Ideal para
- Aplicaciones que toman datos de diferentes fuentes, transforman esos datos y los escriben a diferentes destinos
- Aplicaciones de flujo de trabajo
- Aplicaciones de programación de tareas y trabajos
CQRS
CQRS es un acrónimo de Command and Query Responsibility Segregation. El concepto central de este patrón es que una aplicación tiene operaciones de lectura y operaciones de escritura que deben estar totalmente separadas. Esto también significa que el modelo utilizado para las operaciones de escritura (comandos) será diferente de los modelos de lectura (consultas). Además, los datos se almacenarán en lugares diferentes. En una base de datos relacional, esto significa que habrá tablas para el modelo de comandos y tablas para el modelo de lectura. Algunas implementaciones incluso almacenan los diferentes modelos en bases de datos totalmente diferentes, por ejemplo, SQL Server para el modelo de comandos y MongoDB para el modelo de lectura.
Este patrón se combina a menudo con el suministro de eventos, que cubriremos a continuación.
¿Cómo funciona exactamente? Cuando un usuario realiza una acción, la aplicación envía un comando al servicio de comandos. El servicio de comandos recupera los datos que necesita de la base de datos de comandos, realiza las manipulaciones necesarias y los almacena de nuevo en la base de datos. Luego notifica al servicio de lectura para que el modelo de lectura pueda ser actualizado. Este flujo se puede ver a continuación.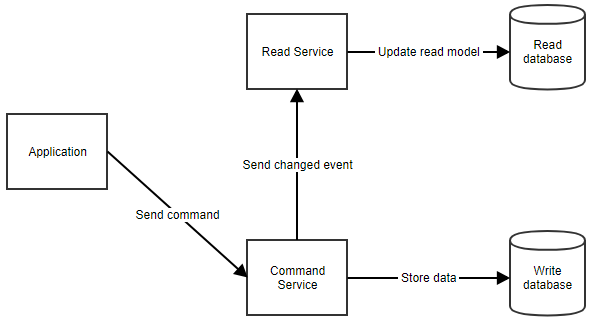
Cuando la aplicación necesita mostrar datos al usuario, puede recuperar el modelo de lectura llamando al servicio de lectura, como se muestra a continuación.
Ventajas
- Los modelos de comandos pueden centrarse en la lógica de negocio y la validación, mientras que los modelos de lectura pueden adaptarse a escenarios específicos.
- Se pueden evitar consultas complejas (por ejemplo joins en SQL), lo que hace que las lecturas tengan un mayor rendimiento.
Desventajas
- Mantener sincronizados los modelos de comando y de lectura puede resultar complejo.
Ideal para
- Aplicaciones que esperan una gran cantidad de lecturas
- Aplicaciones con dominios complejos
Event Sourcing
Como mencioné anteriormente, CQRS suele ir de la mano de event sourcing. Este es un patrón en el que no almacenas el estado actual de tu modelo en la base de datos, sino los eventos que le han ocurrido al modelo. Así, cuando el nombre de un cliente cambia, no se almacena el valor en una columna «Nombre». Se almacenará un evento «NameChanged» con el nuevo valor (y posiblemente el antiguo también).
Cuando se necesita recuperar un modelo, se recuperan todos sus eventos almacenados y se vuelven a aplicar en un nuevo objeto. A esto lo llamamos rehidratar un objeto.
Una analogía de la vida real de la obtención de eventos es la contabilidad. Cuando se añade un gasto, no se cambia el valor del total. En la contabilidad, se añade una nueva línea con la operación a realizar. Si se comete un error, simplemente se añade una nueva línea. Para facilitar la vida, se podría calcular el total cada vez que se añade una línea. Este total puede considerarse como el modelo de lectura. El siguiente ejemplo debería dejarlo más claro.

Puede ver que cometimos un error al añadir la Factura 201805. En lugar de cambiar la línea, añadimos dos nuevas líneas: primero, una para cancelar la línea errónea, y luego una nueva y correcta. Así es como funciona el aprovisionamiento de eventos. Nunca se eliminan los eventos, porque es innegable que han ocurrido en el pasado. Para corregir situaciones, añadimos nuevos eventos.
Además, observe cómo tenemos una celda con el valor total. Esto es simplemente una suma de todos los valores en las celdas anteriores. En Excel, se actualiza automáticamente por lo que se podría decir que se sincroniza con las otras celdas. Es el modelo de lectura, proporcionando una vista fácil para el usuario.
El abastecimiento de eventos se combina a menudo con CQRS porque la rehidratación de un objeto puede tener un impacto en el rendimiento, especialmente cuando hay muchos eventos para la instancia. Un modelo de lectura rápida puede mejorar significativamente el tiempo de respuesta de la aplicación.
Ventajas
- Este patrón de arquitectura de software puede proporcionar un registro de auditoría fuera de la caja. Cada evento representa una manipulación de los datos en un momento determinado.
Desventajas
- Requiere cierta disciplina porque no se pueden arreglar los datos erróneos con una simple edición en la base de datos.
- No es una tarea trivial cambiar la estructura de un evento. Por ejemplo, si añades una propiedad, la base de datos sigue conteniendo eventos sin ese dato. Tu código tendrá que manejar estos datos que faltan con gracia.
Ideal para aplicaciones que
- Necesitan publicar eventos a sistemas externos
- Se construyen con CQRS
- Tienen complejos dominios
- Necesitan un registro de auditoría de los cambios en los datos
Microservicios
Cuando escribes tu aplicación como un conjunto de microservicios, en realidad estás escribiendo múltiples aplicaciones que funcionarán juntas. Cada microservicio tiene su propia responsabilidad distinta y los equipos pueden desarrollarlos independientemente de otros microservicios. La única dependencia entre ellos es la comunicación. Como los microservicios se comunican entre sí, tendrás que asegurarte de que los mensajes que se envíen entre ellos sigan siendo retrocompatibles. Esto requiere cierta coordinación, especialmente cuando diferentes equipos son responsables de diferentes microservicios.
Un diagrama puede explicarlo.
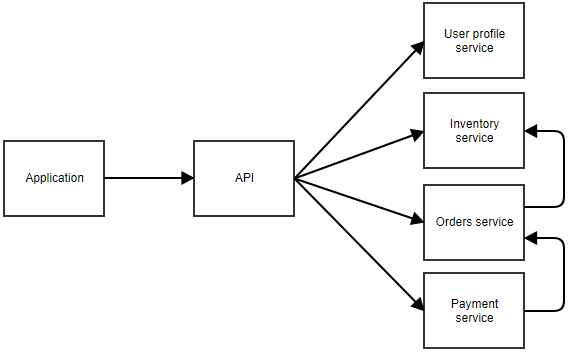 En el diagrama anterior, la aplicación llama a una API central que reenvía la llamada al microservicio correcto. En este ejemplo, hay servicios separados para el perfil del usuario, el inventario, los pedidos y el pago. Puedes imaginar que se trata de una aplicación en la que el usuario puede pedir algo. Los microservicios separados también pueden llamarse entre sí. Por ejemplo, el servicio de pago puede notificar al servicio de pedidos cuando un pago tiene éxito. El servicio de pedidos podría entonces llamar al servicio de inventario para ajustar el stock.
En el diagrama anterior, la aplicación llama a una API central que reenvía la llamada al microservicio correcto. En este ejemplo, hay servicios separados para el perfil del usuario, el inventario, los pedidos y el pago. Puedes imaginar que se trata de una aplicación en la que el usuario puede pedir algo. Los microservicios separados también pueden llamarse entre sí. Por ejemplo, el servicio de pago puede notificar al servicio de pedidos cuando un pago tiene éxito. El servicio de pedidos podría entonces llamar al servicio de inventario para ajustar el stock.
No hay una regla clara de lo grande que puede ser un microservicio. En el ejemplo anterior, el servicio de perfil de usuario puede ser responsable de datos como el nombre de usuario y la contraseña de un usuario, pero también la dirección de casa, la imagen de avatar, los favoritos, etc. También podría ser una opción dividir todas esas responsabilidades en microservicios aún más pequeños.
Ventajas
- Puedes escribir, mantener y desplegar cada microservicio por separado.
- Una arquitectura de microservicios debería ser más fácil de escalar, ya que puedes escalar sólo los microservicios que necesitan ser escalados. No hay necesidad de escalar las piezas de la aplicación que se utilizan con menos frecuencia.
- Es más fácil reescribir piezas de la aplicación porque son más pequeñas y están menos acopladas a otras partes.
Desventajas
- Al contrario de lo que se podría esperar, en realidad es más fácil escribir un monolito bien estructurado al principio y dividirlo en microservicios después. Con los microservicios, entran en juego un montón de preocupaciones adicionales: comunicación, coordinación, compatibilidad con versiones anteriores, registro, etc. Los equipos que no tienen la habilidad necesaria para escribir un monolito bien estructurado probablemente tendrán dificultades para escribir un buen conjunto de microservicios.
- Una sola acción de un usuario puede pasar por múltiples microservicios. Hay más puntos de fallo, y cuando algo va mal, puede llevar más tiempo localizar el problema.
Ideal para:
- Aplicaciones en las que ciertas partes se utilizarán de forma intensiva y necesitan ser escaladas
- Servicios que proporcionan funcionalidad a varias otras aplicaciones
- Aplicaciones que se volverían muy complejas si se combinaran en un monolito
- Aplicaciones en las que se pueden definir contextos claramente delimitados
Combinar
He explicado varios patrones de arquitectura de software, así como sus ventajas y desventajas. Pero hay más patrones que los que he expuesto aquí. Tampoco es raro combinar varios de estos patrones. No siempre son mutuamente excluyentes. Por ejemplo, puedes tener varios microservicios y hacer que algunos de ellos utilicen el patrón de capas, mientras que otros utilizan CQRS y event sourcing.
Lo importante es recordar que no hay una solución que funcione en todas partes. Cuando nos preguntamos qué patrón utilizar para una aplicación, la vieja respuesta sigue siendo válida: «depende». Hay que sopesar los pros y los contras de una solución y tomar una decisión bien informada.