- Esistono molti metodi per testare se una variabile ha una distribuzione normale. In questo articolo, scoprirete quale usare!
- 1.1. Introduzione
- 1.2. Interpretazione
- 1.3. Implementazione
- 1.4. Conclusione
- 2.1. Introduzione
- 2.2 Interpretazione
- 2.3. Implementazione
- 2.4. Conclusione
- 3.1. Introduzione
- 3.2. Interpretazione
- 3.3. Implementazione
- 3.4. Conclusione
- Test Kolmogorov Smirnov
- 4.2. Interpretazione
- 4.3. Implementazione
- 4.4. Conclusione
- Test Lilliefors
- 5.2. Interpretazione
- 5.3. Implementazione
- 5.4. Conclusione
- Test di Shapiro Wilk
- 6.2. Interpretazione
- 6.3. Implementazione
- 6.4. Conclusione
- Conclusione – quale approccio usare!
Esistono molti metodi per testare se una variabile ha una distribuzione normale. In questo articolo, scoprirete quale usare!
1.1. Introduzione
Il primo metodo che quasi tutti conoscono è l’istogramma. L’istogramma è una visualizzazione di dati che mostra la distribuzione di una variabile. Ci dà la frequenza di occorrenza per valore nel set di dati, che è ciò di cui si occupano le distribuzioni.
L’istogramma è un ottimo modo per visualizzare rapidamente la distribuzione di una singola variabile.
1.2. Interpretazione
Nell’immagine qui sotto, due istogrammi mostrano una distribuzione normale e una distribuzione non normale.
- A sinistra, c’è una deviazione molto piccola della distribuzione del campione (in grigio) dalla distribuzione teorica a campana (linea rossa).
- A destra, vediamo una forma molto diversa nell’istogramma, che ci dice direttamente che questa non è una distribuzione normale.

1.3. Implementazione
Un istogramma può essere creato facilmente in python come segue:
1.4. Conclusione
L’istogramma è un ottimo modo per visualizzare rapidamente la distribuzione di una singola variabile.
2.1. Introduzione
Il Box Plot è un’altra tecnica di visualizzazione che può essere usata per rilevare campioni non normali. Il Box Plot traccia il riassunto di 5 numeri di una variabile: minimo, primo quartile, mediana, terzo quartile e massimo.
Il boxplot è un ottimo modo per visualizzare le distribuzioni di più variabili allo stesso tempo.
2.2 Interpretazione
Il boxplot è una grande tecnica di visualizzazione perché permette di tracciare molti boxplot uno accanto all’altro. Avere questa panoramica molto veloce delle variabili ci dà un’idea della distribuzione e come “bonus”, otteniamo il riassunto completo di 5 numeri che ci aiuterà in ulteriori analisi.
Si dovrebbero guardare due cose:
- La distribuzione è simmetrica (come la distribuzione normale)?
- L’ampiezza (opposta alla puntualità) corrisponde all’ampiezza della distribuzione normale? Questo è difficile da vedere su un box plot.

2.3. Implementazione
Un boxplot può essere facilmente implementato in python come segue:
2.4. Conclusione
Il boxplot è un ottimo modo per visualizzare le distribuzioni di più variabili allo stesso tempo, ma una deviazione nella larghezza/punto è difficile da identificare usando i box plot.
3.1. Introduzione
Con i diagrammi QQ cominciamo ad entrare nelle cose più serie, poiché questo richiede un po’ più di comprensione rispetto ai metodi descritti in precedenza.
QQ Plot sta per Quantile vs Quantile Plot, che è esattamente quello che fa: tracciare i quantili teorici contro i quantili reali della nostra variabile.
Il QQ Plot ci permette di vedere la deviazione di una distribuzione normale molto meglio che in un Istogramma o Box Plot.
3.2. Interpretazione
Se la nostra variabile segue una distribuzione normale, i quantili della nostra variabile devono essere perfettamente in linea con i quantili normali “teorici”: una linea retta sul grafico QQ ci dice che abbiamo una distribuzione normale.
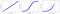
Come si vede nell’immagine, i punti su un normale QQ Plot seguono una linea retta, mentre altre distribuzioni deviano fortemente.
- La distribuzione uniforme ha troppe osservazioni in entrambe le estremità (valori molto alti e molto bassi).
- La distribuzione esponenziale ha troppe osservazioni nei valori più bassi, ma troppo poche nei valori più alti.
In pratica, spesso vediamo qualcosa di meno pronunciato ma di forma simile. Una sovrarappresentazione o sottorappresentazione nella coda dovrebbe causare dubbi sulla normalità, nel qual caso si dovrebbe usare uno dei test di ipotesi descritti di seguito.
3.3. Implementazione
L’implementazione di un grafico QQ può essere fatta usando l’api statsmodels in python come segue:
3.4. Conclusione
Il diagramma QQ ci permette di vedere la deviazione di una distribuzione normale molto meglio che in un istogramma o box plot.
Test Kolmogorov Smirnov
Se il diagramma QQ e altre tecniche di visualizzazione non sono conclusivi, l’inferenza statistica (test di ipotesi) può dare una risposta più obiettiva per sapere se la nostra variabile devia significativamente da una distribuzione normale.
Se avete dubbi su come e quando usare il test di ipotesi, ecco un articolo che dà una spiegazione intuitiva al test di ipotesi.
Il test di Kolmogorov Smirnov calcola le distanze tra la distribuzione empirica e la distribuzione teorica e definisce la statistica del test come il supremo dell’insieme di queste distanze.
Il vantaggio di questo è che lo stesso approccio può essere usato per confrontare qualsiasi distribuzione, non necessariamente la sola distribuzione normale.
Il test KS è ben noto ma non ha molta potenza. Può essere usato per distribuzioni diverse dalla normale.
4.2. Interpretazione
La statistica del test KS è la statistica di Kolmogorov Smirnov, che segue una distribuzione di Kolmogorov se l’ipotesi nulla è vera.
Se i dati osservati seguono perfettamente una distribuzione normale, il valore della statistica KS sarà 0. Il valore P viene usato per decidere se la differenza è abbastanza grande da rifiutare l’ipotesi nulla:
- Se il valore P del test di KS è più grande di 0,05, si assume una distribuzione normale
- Se il valore P del test di KS è più piccolo di 0,05, non si assume una distribuzione normale
4.3. Implementazione
Il test di KS in Python usando Scipy può essere implementato come segue. Restituisce la statistica KS e il suo valore P.
4.4. Conclusione
Il test KS è ben noto ma non ha molta potenza. Ciò significa che è necessario un gran numero di osservazioni per rifiutare l’ipotesi nulla. È anche sensibile agli outlier. D’altra parte, può essere usato per altri tipi di distribuzioni.
Test Lilliefors
Il test Lilliefors è fortemente basato sul test KS. La differenza è che nel test di Lilliefors, si accetta che la media e la varianza della distribuzione della popolazione siano stimate piuttosto che pre-specificate dall’utente.
Per questo motivo, il test di Lilliefors usa la distribuzione di Lilliefors piuttosto che la distribuzione di Kolmogorov.
Purtroppo per Lilliefors, la sua potenza è ancora inferiore al test di Shapiro Wilk.
5.2. Interpretazione
- Se il valore P del test di Lilliefors è maggiore di 0,05, assumiamo una distribuzione normale
- Se il valore P del test di Lilliefors è minore di 0,05, non assumiamo una distribuzione normale
5.3. Implementazione
L’implementazione del test di Lilliefors in statsmodels restituisce il valore della statistica del test di Lilliefors e il valore P come segue.
Attenzione: nell’implementazione di statsmodels, i valori P inferiori a 0.001 sono riportati come 0.001 e il valore P come 0.05.001 sono riportati come 0,001 e i valori P superiori a 0,2 sono riportati come 0,2.
5.4. Conclusione
Anche se Lilliefors è un miglioramento del test KS la sua potenza è ancora inferiore al test di Shapiro Wilk.
Test di Shapiro Wilk
Il test di Shapiro Wilk è il test più potente quando si verifica una distribuzione normale. È stato sviluppato specificamente per la distribuzione normale e non può essere usato per test contro altre distribuzioni come per esempio il test KS.
Il test di Shapiro Wilk è il test più potente quando si testa una distribuzione normale.
6.2. Interpretazione
- Se il valore P del test di Shapiro Wilk è più grande di 0,05, si assume una distribuzione normale
- Se il valore P del test di Shapiro Wilk è più piccolo di 0,05, non si assume una distribuzione normale
6.3. Implementazione
Il test di Shapiro Wilk può essere implementato come segue. Restituirà la statistica del test chiamata W e il valore P.
Attenzione: per N > 5000 la statistica del test W è accurata ma il valore P potrebbe non esserlo.
6.4. Conclusione
Il test di Shapiro Wilk è il test più potente quando si verifica una distribuzione normale. Dovresti assolutamente usare questo test.
Conclusione – quale approccio usare!
Per una rapida e visiva identificazione di una distribuzione normale, usa un grafico QQ se hai solo una variabile da guardare e un Box Plot se ne hai molte. Usate un istogramma se dovete presentare i vostri risultati a un pubblico non statistico.
Come test statistico per confermare la vostra ipotesi, usate il test di Shapiro Wilk. È il test più potente, che dovrebbe essere l’argomento decisivo.
Quando testate contro altre distribuzioni, non potete usare Shapiro Wilk e dovreste usare per esempio il test di Anderson-Darling o il test KS.