Quando frequentavo la scuola serale per diventare programmatore, ho imparato diversi design pattern: singleton, repository, factory, builder, decorator, ecc. I design pattern ci danno una soluzione collaudata a problemi esistenti e ricorrenti. Quello che non ho imparato è che un meccanismo simile esiste ad un livello superiore: i pattern di architettura del software. Questi sono pattern per il layout generale della vostra applicazione o delle vostre applicazioni. Hanno tutti vantaggi e svantaggi. E tutti affrontano problemi specifici.
Layered Pattern
Il layered pattern è probabilmente uno dei più noti pattern di architettura software. Molti sviluppatori lo usano, senza conoscerne il nome. L’idea è di dividere il codice in “strati”, dove ogni strato ha una certa responsabilità e fornisce un servizio ad uno strato superiore.
Non c’è un numero predefinito di livelli, ma questi sono quelli che si vedono più spesso:
- Strato di presentazione o UI
- Strato di applicazione
- Strato di business o di dominio
- Strato di persistenza o di accesso ai dati
- Strato del database
L’idea è che l’utente inizi un pezzo di codice nel livello di presentazione eseguendo qualche azione (es.ad esempio cliccando un pulsante). Il livello di presentazione poi chiama il livello sottostante, cioè il livello di applicazione. Poi si passa al livello di business e, infine, il livello di persistenza memorizza tutto nel database. Quindi i livelli superiori dipendono e fanno chiamate ai livelli inferiori.

Vedrai variazioni di questo, a seconda della complessità delle applicazioni. Alcune applicazioni possono omettere il livello dell’applicazione, mentre altre aggiungono un livello di caching. È anche possibile fondere due livelli in uno solo. Per esempio, il pattern ActiveRecord combina i livelli di business e di persistenza.
Responsabilità dei livelli
Come detto, ogni livello ha la sua responsabilità. Il livello di presentazione contiene il design grafico dell’applicazione, così come qualsiasi codice per gestire l’interazione dell’utente. Non dovresti aggiungere logica che non sia specifica per l’interfaccia utente in questo livello.
Il livello di business è dove metti i modelli e la logica che è specifica per il problema di business che stai cercando di risolvere.
Il livello di applicazione si trova tra il livello di presentazione e quello di business. Da un lato, fornisce un’astrazione in modo che il livello di presentazione non abbia bisogno di conoscere il livello di business. In teoria, potresti cambiare lo stack tecnologico del livello di presentazione senza cambiare nient’altro nella tua applicazione (ad es. passare da WinForms a WPF). D’altra parte, il livello dell’applicazione fornisce un posto dove mettere certa logica di coordinamento che non si adatta al livello di business o di presentazione.
Infine, il livello di persistenza contiene il codice per accedere al livello del database. Il livello del database è la tecnologia del database sottostante (ad esempio SQL Server, MongoDB). Il livello di persistenza è l’insieme di codice per manipolare il database:
Svantaggi
- La maggior parte degli sviluppatori ha familiarità con questo modello.
- Fornisce un modo semplice di scrivere un’applicazione ben organizzata e testabile.
Svantaggi
- Tende a portare ad applicazioni monolitiche che sono difficili da dividere in seguito.
- Gli sviluppatori spesso si trovano a scrivere molto codice per passare attraverso i diversi strati, senza aggiungere alcun valore in questi strati. Se tutto quello che state facendo è scrivere una semplice applicazione CRUD, il pattern a strati potrebbe essere eccessivo per voi.
Ideale per
- Applicazioni line-of-business standard che fanno più che semplici operazioni CRUD
Microkernel
Il pattern microkernel, o pattern plug-in, è utile quando la tua applicazione ha un nucleo di responsabilità e una collezione di parti intercambiabili sul lato. Il microkernel fornirà il punto di ingresso e il flusso generale dell’applicazione, senza sapere realmente cosa stanno facendo i diversi plug-in.
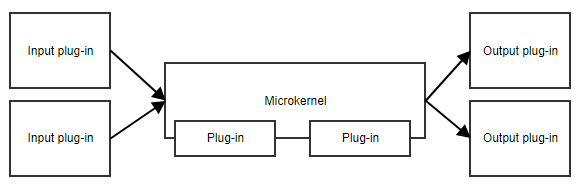
Un esempio è un task scheduler. Il microkernel potrebbe contenere tutta la logica per la programmazione e l’attivazione dei compiti, mentre i plug-in contengono compiti specifici. Finché i plug-in aderiscono a un’API predefinita, il microkernel può attivarli senza bisogno di conoscere i dettagli dell’implementazione.
Un altro esempio è un flusso di lavoro. L’implementazione di un flusso di lavoro contiene concetti come l’ordine dei diversi passi, valutare i risultati dei passi, decidere quale sia il passo successivo, ecc. L’implementazione specifica dei passi è meno importante del codice di base del flusso di lavoro.
Avantaggi
- Questo modello fornisce grande flessibilità ed estensibilità.
- Alcune implementazioni permettono di aggiungere plug-in mentre l’applicazione è in esecuzione.
- Microkernel e plug-in possono essere sviluppati da team separati.
Svantaggi
- Può essere difficile decidere cosa appartiene al microkernel e cosa no.
- L’API predefinita potrebbe non essere una buona soluzione per i futuri plug-in.
Ideale per
- Applicazioni che prendono dati da diverse fonti, trasformano quei dati e li scrivono a diverse destinazioni
- Applicazioni per flussi di lavoro
- Applicazioni per la programmazione di compiti e lavori
CQRS
CQRS è un acronimo per Command and Query Responsibility Segregation. Il concetto centrale di questo pattern è che un’applicazione ha operazioni di lettura e scrittura che devono essere totalmente separate. Questo significa anche che il modello utilizzato per le operazioni di scrittura (comandi) sarà diverso dai modelli di lettura (query). Inoltre, i dati saranno memorizzati in luoghi diversi. In un database relazionale, questo significa che ci saranno tabelle per il modello di comando e tabelle per il modello di lettura. Alcune implementazioni memorizzano anche i diversi modelli in database completamente diversi, ad esempio SQL Server per il modello di comando e MongoDB per il modello di lettura.
Questo modello è spesso combinato con l’event sourcing, che tratteremo di seguito.
Come funziona esattamente? Quando un utente esegue un’azione, l’applicazione invia un comando al servizio di comando. Il servizio di comando recupera tutti i dati di cui ha bisogno dal database dei comandi, effettua le manipolazioni necessarie e li memorizza nel database. Poi notifica il servizio di lettura in modo che il modello di lettura possa essere aggiornato. Questo flusso può essere visto qui sotto.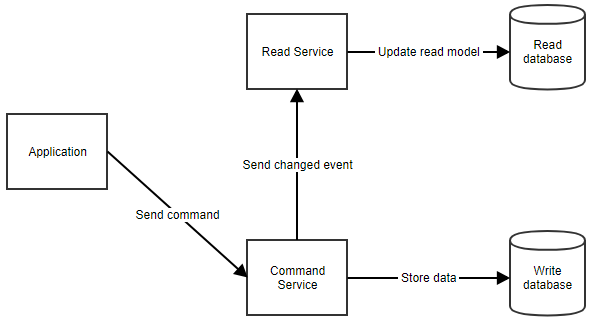
Quando l’applicazione ha bisogno di mostrare i dati all’utente, può recuperare il modello di lettura chiamando il servizio di lettura, come mostrato qui sotto.
Vantaggi
- I modelli di comando possono concentrarsi sulla logica di business e sulla validazione mentre i modelli di lettura possono essere adattati a scenari specifici.
- Si possono evitare query complesse (es. join in SQL) che rende le letture più performanti.
Svantaggi
- Mantenere il comando e i modelli di lettura sincronizzati può diventare complesso.
Ideale per
- Applicazioni che si aspettano un’alta quantità di letture
- Applicazioni con domini complessi
Event Sourcing
Come ho detto sopra, CQRS spesso va di pari passo con event sourcing. Questo è un modello in cui non si memorizza lo stato attuale del modello nel database, ma piuttosto gli eventi che sono accaduti al modello. Così quando il nome di un cliente cambia, non si memorizza il valore in una colonna “Name”. Memorizzerete un evento “NameChanged” con il nuovo valore (e possibilmente anche quello vecchio).
Quando avete bisogno di recuperare un modello, recuperate tutti i suoi eventi memorizzati e li riapplicate ad un nuovo oggetto. Questo si chiama reidratare un oggetto.
Un’analogia della vita reale dell’event sourcing è la contabilità. Quando si aggiunge una spesa, non si cambia il valore del totale. Nella contabilità, si aggiunge una nuova riga con l’operazione da eseguire. Se è stato fatto un errore, si aggiunge semplicemente una nuova riga. Per facilitare la vita, si potrebbe calcolare il totale ogni volta che si aggiunge una riga. Questo totale può essere considerato come il modello di lettura. L’esempio qui sotto dovrebbe renderlo più chiaro.

Si può vedere che abbiamo fatto un errore quando abbiamo aggiunto Invoice 201805. Invece di cambiare la linea, abbiamo aggiunto due nuove linee: prima una per cancellare la linea sbagliata, poi una nuova linea corretta. Questo è il modo in cui funziona l’event sourcing. Non si rimuovono mai gli eventi, perché sono innegabilmente accaduti in passato. Per correggere le situazioni, aggiungiamo nuovi eventi.
Nota anche come abbiamo una cella con il valore totale. Questo è semplicemente una somma di tutti i valori nelle celle precedenti. In Excel, si aggiorna automaticamente, quindi si potrebbe dire che si sincronizza con le altre celle. È il modello di lettura, che fornisce una facile visualizzazione per l’utente.
L’event sourcing è spesso combinato con CQRS perché reidratare un oggetto può avere un impatto sulle prestazioni, specialmente quando ci sono molti eventi per l’istanza. Un modello di lettura veloce può migliorare significativamente il tempo di risposta dell’applicazione.
Avantaggi
- Questo modello di architettura software può fornire un registro di controllo fuori dalla scatola. Ogni evento rappresenta una manipolazione dei dati in un certo momento.
Svantaggi
- Richiede una certa disciplina perché non si possono correggere dati sbagliati con una semplice modifica nel database.
- Non è un compito banale cambiare la struttura di un evento. Per esempio, se aggiungi una proprietà, il database contiene ancora eventi senza quei dati. Il tuo codice dovrà gestire graziosamente questi dati mancanti.
Ideale per applicazioni che
- Necessitano di pubblicare eventi a sistemi esterni
- Saranno costruite con CQRS
- Hanno complessi complessi
- Hanno bisogno di un registro di controllo delle modifiche ai dati
Microservizi
Quando scrivi la tua applicazione come un insieme di microservizi, stai effettivamente scrivendo più applicazioni che lavoreranno insieme. Ogni microservizio ha la sua responsabilità distinta e i team possono svilupparli indipendentemente dagli altri microservizi. L’unica dipendenza tra loro è la comunicazione. Poiché i microservizi comunicano tra loro, dovrete assicurarvi che i messaggi inviati tra di loro rimangano compatibili all’indietro. Questo richiede una certa coordinazione, specialmente quando diversi team sono responsabili di diversi microservizi.
Un diagramma può spiegare.
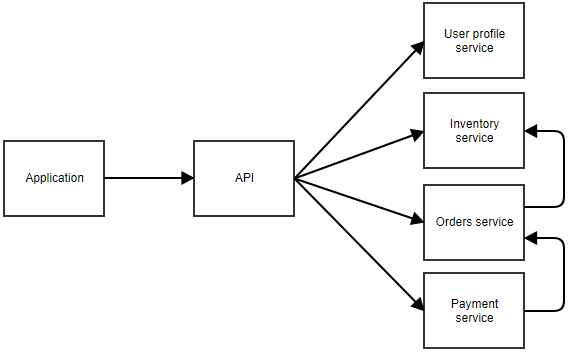 Nel diagramma precedente, l’applicazione chiama un’API centrale che inoltra la chiamata al microservizio corretto. In questo esempio, ci sono servizi separati per il profilo utente, l’inventario, gli ordini e il pagamento. Potete immaginare che questa sia un’applicazione dove l’utente può ordinare qualcosa. Anche i microservizi separati possono chiamarsi a vicenda. Per esempio, il servizio di pagamento potrebbe notificare il servizio ordini quando un pagamento ha successo. Il servizio ordini potrebbe poi chiamare il servizio inventario per regolare lo stock.
Nel diagramma precedente, l’applicazione chiama un’API centrale che inoltra la chiamata al microservizio corretto. In questo esempio, ci sono servizi separati per il profilo utente, l’inventario, gli ordini e il pagamento. Potete immaginare che questa sia un’applicazione dove l’utente può ordinare qualcosa. Anche i microservizi separati possono chiamarsi a vicenda. Per esempio, il servizio di pagamento potrebbe notificare il servizio ordini quando un pagamento ha successo. Il servizio ordini potrebbe poi chiamare il servizio inventario per regolare lo stock.
Non c’è una regola chiara su quanto grande possa essere un microservizio. Nell’esempio precedente, il servizio profilo utente potrebbe essere responsabile di dati come il nome utente e la password di un utente, ma anche l’indirizzo di casa, l’immagine dell’avatar, i preferiti, ecc. Potrebbe anche essere un’opzione per dividere tutte queste responsabilità in microservizi ancora più piccoli.
Svantaggi
- Puoi scrivere, mantenere e distribuire ogni microservizio separatamente.
- Un’architettura a microservizi dovrebbe essere più facile da scalare, poiché puoi scalare solo i microservizi che devono essere scalati. Non c’è bisogno di scalare i pezzi dell’applicazione usati meno frequentemente.
- È più facile riscrivere pezzi dell’applicazione perché sono più piccoli e meno accoppiati ad altre parti.
Svantaggi
- Contrariamente a quanto ci si potrebbe aspettare, è effettivamente più facile scrivere un monolite ben strutturato all’inizio e dividerlo in microservizi più tardi. Con i microservizi, entrano in gioco un sacco di preoccupazioni extra: comunicazione, coordinamento, retrocompatibilità, log, ecc. I team a cui manca l’abilità necessaria per scrivere un monolite ben strutturato probabilmente avranno difficoltà a scrivere un buon insieme di microservizi.
- Una singola azione di un utente può passare attraverso più microservizi. Ci sono più punti di fallimento, e quando qualcosa va storto, può richiedere più tempo per individuare il problema.
Ideale per:
- Applicazioni dove certe parti saranno usate intensamente e devono essere scalate
- Servizi che forniscono funzionalità a diverse altre applicazioni
- Applicazioni che diventerebbero molto complesse se combinate in un monolite
- Applicazioni dove possono essere definiti chiari contesti delimitati
Combina
Ho spiegato diversi modelli di architettura software, così come i loro vantaggi e svantaggi. Ma ci sono altri modelli oltre a quelli che ho esposto qui. Inoltre non è raro combinare diversi di questi modelli. Non sempre si escludono a vicenda. Per esempio, si potrebbero avere diversi microservizi e avere alcuni di essi che usano il pattern a strati, mentre altri usano CQRS e event sourcing.
La cosa importante da ricordare è che non c’è una soluzione che funziona ovunque. Quando ci poniamo la domanda su quale pattern usare per un’applicazione, la vecchia risposta è ancora valida: “dipende”. Dovreste valutare i pro e i contro di una soluzione e prendere una decisione ben informata.