Toen ik naar de avondschool ging om programmeur te worden, leerde ik verschillende design patterns: singleton, repository, factory, builder, decorator, enz. Design patterns geven ons een bewezen oplossing voor bestaande en terugkerende problemen. Wat ik niet leerde was dat een soortgelijk mechanisme bestaat op een hoger niveau: software architectuur patronen. Dit zijn patronen voor de algemene lay-out van je applicatie of applicaties. Ze hebben allemaal voor- en nadelen. En ze pakken allemaal specifieke problemen aan.
Layered Pattern
Het gelaagde patroon is waarschijnlijk een van de bekendste software architectuur patronen. Veel ontwikkelaars gebruiken het, zonder echt de naam te kennen. Het idee is om je code op te delen in “lagen”, waarbij elke laag een bepaalde verantwoordelijkheid heeft en een dienst verleent aan een hogere laag.
Er is geen vooraf bepaald aantal lagen, maar dit zijn de lagen die je het vaakst ziet:
- Presentatie- of UI-laag
- Applicatielaag
- Business- of domeinlaag
- Persistentie- of datatoegangslaag
- Database-laag
Het idee is dat de gebruiker een stukje code in de presentatielaag initieert door een of andere actie uit te voeren (bijv.b.v. het klikken op een knop). De presentatielaag roept vervolgens de onderliggende laag aan, d.w.z. de toepassingslaag. Dan komt de bedrijfslaag aan de beurt en tenslotte slaat de persistentielaag alles op in de database. Hogere lagen zijn dus afhankelijk van en doen een beroep op de lagere lagen.

Je zult hier variaties in zien, afhankelijk van de complexiteit van de toepassingen. Sommige toepassingen kunnen de toepassingslaag weglaten, terwijl andere een caching-laag toevoegen. Het is zelfs mogelijk om twee lagen samen te voegen tot één. Bijvoorbeeld, het ActiveRecord patroon combineert de business en persistentie lagen.
Laag Verantwoordelijkheid
Zoals gezegd, heeft elke laag zijn eigen verantwoordelijkheid. De presentatielaag bevat het grafische ontwerp van de toepassing, evenals alle code om de interactie tussen gebruikers te verwerken. In deze laag moet u geen logica toevoegen die niet specifiek is voor de gebruikersinterface.
In de bedrijfslaag plaatst u de modellen en logica die specifiek zijn voor het bedrijfsprobleem dat u probeert op te lossen.
De applicatielaag zit tussen de presentatielaag en de bedrijfslaag in. Aan de ene kant biedt het een abstractie, zodat de presentatielaag de bedrijfslaag niet hoeft te kennen. In theorie zou u de technologie-stack van de presentatielaag kunnen veranderen zonder iets anders in uw applicatie te veranderen (bijv. overstappen van WinForms naar WPF). Aan de andere kant biedt de applicatielaag een plaats om bepaalde coördinatielogica te plaatsen die niet in de bedrijfs- of presentatielaag past.
Ten slotte bevat de persistentielaag de code om toegang te krijgen tot de databaselaag. De databaselaag is de onderliggende databasetechnologie (b.v. SQL Server, MongoDB). De persistentie laag is de set van code om de database te manipuleren: SQL statements, verbindingsdetails, etc.
Voordelen
- De meeste ontwikkelaars zijn bekend met dit patroon.
- Het biedt een eenvoudige manier om een goed georganiseerde en testbare applicatie te schrijven.
Nadelen
- Het heeft de neiging om te leiden tot monolithische applicaties die achteraf moeilijk te splitsen zijn.
- Ontwikkelaars merken vaak dat ze veel code schrijven om door de verschillende lagen heen te komen, zonder enige waarde toe te voegen in deze lagen. Als alles wat je doet is het schrijven van een eenvoudige CRUD applicatie, kan de gelaagde patroon overkill voor je zijn.
Ideaal voor
- Standaard line-of-business apps die meer doen dan alleen CRUD operaties
Microkernel
Het microkernel patroon, of plug-in patroon, is nuttig wanneer uw applicatie een kernset van verantwoordelijkheden heeft en een verzameling van uitwisselbare onderdelen aan de zijkant. De microkernel zorgt voor het ingangspunt en de algemene stroom van de applicatie, zonder echt te weten wat de verschillende plug-ins doen.
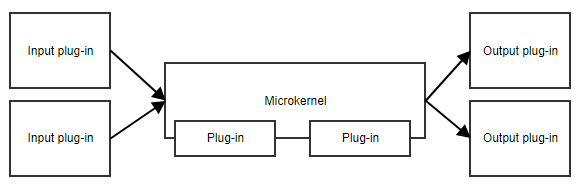
Een voorbeeld is een taakplanner. De microkernel zou alle logica voor het plannen en activeren van taken kunnen bevatten, terwijl de plug-ins specifieke taken bevatten. Zolang de plug-ins zich houden aan een vooraf gedefinieerde API, kan de microkernel ze starten zonder dat hij de implementatiedetails hoeft te kennen.
Een ander voorbeeld is een workflow. De implementatie van een workflow bevat concepten als de volgorde van de verschillende stappen, het evalueren van de resultaten van de stappen, het bepalen wat de volgende stap is, enz. De specifieke implementatie van de stappen is minder belangrijk voor de kerncode van de workflow.
Voordelen
- Dit patroon biedt grote flexibiliteit en uitbreidbaarheid.
- Sommige implementaties maken het mogelijk om plug-ins toe te voegen terwijl de applicatie draait.
- Microkernel en plug-ins kunnen door afzonderlijke teams worden ontwikkeld.
Nadelen
- Het kan moeilijk zijn om te beslissen wat in de microkernel thuishoort en wat niet.
- De voorgedefinieerde API zou wel eens niet goed kunnen zijn voor toekomstige plug-ins.
Ideaal voor
- Applicaties die gegevens uit verschillende bronnen halen, die gegevens transformeren en ze naar verschillende bestemmingen schrijven
- Workflow-applicaties
- Task and job scheduling applications
CQRS
CQRS is een acroniem voor Command and Query Responsibility Segregation. Het centrale concept van dit patroon is dat een applicatie leesbewerkingen en schrijfbewerkingen heeft die volledig gescheiden moeten zijn. Dit betekent ook dat het model dat gebruikt wordt voor schrijfoperaties (commands) zal verschillen van de leesmodellen (queries). Bovendien zullen de gegevens op verschillende plaatsen worden opgeslagen. In een relationele database betekent dit dat er tabellen zullen zijn voor het opdrachtmodel en tabellen voor het leesmodel. Sommige implementaties slaan de verschillende modellen zelfs op in totaal verschillende databases, bijvoorbeeld SQL Server voor het opdrachtmodel en MongoDB voor het leesmodel.
Dit patroon wordt vaak gecombineerd met event sourcing, dat we hieronder zullen behandelen.
Hoe werkt het precies? Wanneer een gebruiker een actie uitvoert, stuurt de applicatie een commando naar de command service. De commandoservice haalt de benodigde gegevens op uit de commandodatabase, bewerkt ze en slaat ze weer op in de database. Vervolgens wordt de leesservice op de hoogte gebracht, zodat het leesmodel kan worden bijgewerkt. Deze stroom is hieronder te zien.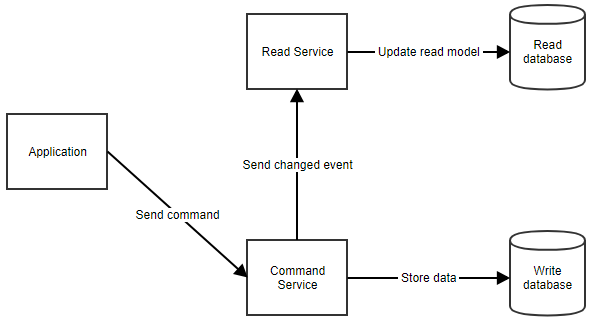
Wanneer de toepassing gegevens aan de gebruiker moet tonen, kan deze het gelezen model ophalen door de read service aan te roepen, zoals hieronder te zien is.
Voordelen
- Command-modellen kunnen zich richten op bedrijfslogica en validatie, terwijl read-modellen kunnen worden toegesneden op specifieke scenario’s.
- U kunt complexe query’s vermijden (bijv. joins in SQL), waardoor het lezen performanter wordt.
Nadelen
- Het synchroon houden van het opdrachtmodel en het leesmodel kan complex worden.
Ideaal voor
- Applicaties die een grote hoeveelheid reads verwachten
- Applicaties met complexe domeinen
Event Sourcing
Zoals ik hierboven al zei, gaat CQRS vaak hand in hand met event sourcing. Dit is een patroon waarbij je niet de huidige toestand van je model in de database opslaat, maar wel de gebeurtenissen die met het model zijn gebeurd. Dus wanneer de naam van een klant verandert, zul je de waarde niet opslaan in een “Name” kolom. Je slaat een “NameChanged” event op met de nieuwe waarde (en mogelijk ook de oude).
Wanneer je een model moet ophalen, haal je al zijn opgeslagen events op en past ze opnieuw toe op een nieuw object. We noemen dit rehydrating een object.
Een real-life analogie van event sourcing is de boekhouding. Wanneer je een uitgave toevoegt, verander je niet de waarde van het totaal. In de boekhouding wordt een nieuwe regel toegevoegd met de uit te voeren bewerking. Als er een fout is gemaakt, voeg je gewoon een nieuwe regel toe. Om het u gemakkelijker te maken, zou u het totaal kunnen berekenen telkens wanneer u een regel toevoegt. Dit totaal kan worden beschouwd als het leesmodel. Het onderstaande voorbeeld moet het duidelijker maken.

U kunt zien dat we een fout hebben gemaakt bij het toevoegen van Factuur 201805. In plaats van de regel te wijzigen, hebben we twee nieuwe regels toegevoegd: eerst een om de verkeerde regel te annuleren, daarna een nieuwe en juiste regel. Dit is hoe event sourcing werkt. Je verwijdert nooit gebeurtenissen, omdat ze ontegenzeggelijk in het verleden hebben plaatsgevonden. Om situaties te corrigeren, voegen we nieuwe gebeurtenissen toe.
Merk ook op dat we een cel hebben met de totale waarde. Dit is gewoon een som van alle waarden in de cellen hierboven. In Excel wordt deze automatisch bijgewerkt, dus je zou kunnen zeggen dat hij synchroniseert met de andere cellen. Het is het leesmodel, dat de gebruiker een gemakkelijk overzicht biedt.
Event sourcing wordt vaak gecombineerd met CQRS, omdat het rehydrateren van een object gevolgen kan hebben voor de prestaties, vooral als er veel events voor de instantie zijn. Een fast read model kan de responstijd van de applicatie aanzienlijk verbeteren.
Voordelen
- Dit software architectuur patroon kan een audit log out of the box leveren. Elke gebeurtenis vertegenwoordigt een manipulatie van de gegevens op een bepaald moment.
Voordelen
- Het vereist enige discipline, omdat je niet zomaar verkeerde gegevens kunt herstellen met een eenvoudige bewerking in de database.
- Het is geen triviale taak om de structuur van een gebeurtenis te veranderen. Bijvoorbeeld, als u een eigenschap toevoegt, bevat de database nog steeds gebeurtenissen zonder die gegevens. Uw code zal genadig met deze ontbrekende gegevens moeten omgaan.
Ideaal voor toepassingen die
- gebeurtenissen moeten publiceren naar externe systemen
- Wordt gebouwd met CQRS
- Zijn complexe domeinen
- Een audit log nodig van wijzigingen in de data
Microservices
Wanneer je je applicatie schrijft als een set microservices, schrijf je eigenlijk meerdere applicaties die samen zullen werken. Elke microservice heeft zijn eigen verantwoordelijkheid en teams kunnen ze onafhankelijk van andere microservices ontwikkelen. De enige afhankelijkheid tussen hen is de communicatie. Omdat microservices met elkaar communiceren, zul je ervoor moeten zorgen dat berichten die tussen hen worden verzonden, achterwaarts compatibel blijven. Dit vereist enige coördinatie, vooral wanneer verschillende teams verantwoordelijk zijn voor verschillende microservices.
Een diagram kan dit verduidelijken.
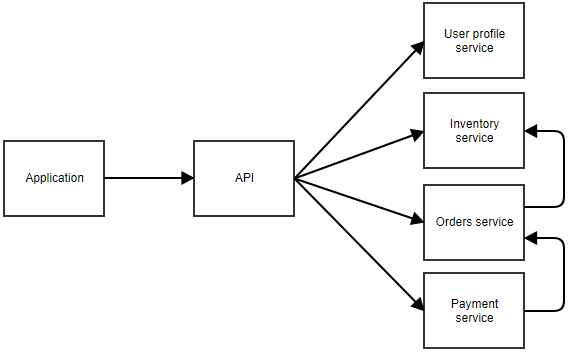 In bovenstaand diagram roept de applicatie een centrale API aan die de call doorstuurt naar de juiste microservice. In dit voorbeeld zijn er afzonderlijke services voor het gebruikersprofiel, de voorraad, de bestellingen en de betaling. Je kunt je voorstellen dat dit een applicatie is waar de gebruiker iets kan bestellen. De afzonderlijke microservices kunnen elkaar ook aanroepen. Bijvoorbeeld, de betaalservice kan de bestelservice op de hoogte stellen wanneer een betaling slaagt. De bestelservice zou dan de inventarisservice kunnen aanroepen om de voorraad aan te passen.
In bovenstaand diagram roept de applicatie een centrale API aan die de call doorstuurt naar de juiste microservice. In dit voorbeeld zijn er afzonderlijke services voor het gebruikersprofiel, de voorraad, de bestellingen en de betaling. Je kunt je voorstellen dat dit een applicatie is waar de gebruiker iets kan bestellen. De afzonderlijke microservices kunnen elkaar ook aanroepen. Bijvoorbeeld, de betaalservice kan de bestelservice op de hoogte stellen wanneer een betaling slaagt. De bestelservice zou dan de inventarisservice kunnen aanroepen om de voorraad aan te passen.
Er is geen duidelijke regel voor hoe groot een microservice mag zijn. In het vorige voorbeeld kan de gebruikersprofielservice verantwoordelijk zijn voor gegevens als de gebruikersnaam en het wachtwoord van een gebruiker, maar ook het huisadres, avatarafbeelding, favorieten, enzovoort. Het zou ook een optie kunnen zijn om al die verantwoordelijkheden op te splitsen in nog kleinere microservices.
Voordelen
- Je kunt elke microservice afzonderlijk schrijven, onderhouden en uitrollen.
- Een microservices-architectuur zou eenvoudiger te schalen moeten zijn, omdat je alleen de microservices kunt schalen die geschaald moeten worden. Het is niet nodig om de minder vaak gebruikte stukken van de applicatie te schalen.
- Het is gemakkelijker om stukken van de applicatie te herschrijven, omdat ze kleiner zijn en minder gekoppeld zijn aan andere onderdelen.
Nadelen
- In tegenstelling tot wat je zou verwachten, is het eigenlijk gemakkelijker om eerst een goed gestructureerde monoliet te schrijven en deze later op te splitsen in microservices. Met microservices komen er veel extra zorgen bij kijken: communicatie, coördinatie, achterwaartse compatibiliteit, logging, etc. Teams die de vaardigheid missen om een goed gestructureerde monoliet te schrijven, zullen het waarschijnlijk moeilijk hebben om een goede set microservices te schrijven.
- Een enkele actie van een gebruiker kan door meerdere microservices gaan. Er zijn meer punten van mislukking, en als er iets misgaat, kan het meer tijd kosten om het probleem te lokaliseren.
Ideaal voor:
- Applicaties waarbij bepaalde onderdelen intensief gebruikt zullen worden en geschaald moeten worden
- Services die functionaliteit bieden aan verschillende andere applicaties
- Applicaties die erg complex zouden worden als ze tot één monoliet gecombineerd zouden worden
- Applicaties waarbij duidelijke begrensde contexten gedefinieerd kunnen worden
Combine
Ik heb verschillende software architectuurpatronen uitgelegd, en hun voor- en nadelen. Maar er zijn meer patronen dan die ik hier heb uiteengezet. Het is ook niet ongebruikelijk om verschillende van deze patronen te combineren. Ze sluiten elkaar niet altijd uit. Je zou bijvoorbeeld verschillende microservices kunnen hebben en sommige daarvan het gelaagde patroon laten gebruiken, terwijl andere CQRS en event sourcing gebruiken.
Het belangrijkste om te onthouden is dat er niet één oplossing is die overal werkt. Als we de vraag stellen welk patroon te gebruiken voor een toepassing, geldt nog steeds het eeuwenoude antwoord: “Dat hangt ervan af.” Je moet de voor- en nadelen van een oplossing tegen elkaar afwegen en een weloverwogen beslissing nemen.