Quando eu estava freqüentando a escola noturna para me tornar um programador, eu aprendi vários padrões de design: singleton, repositório, fábrica, construtor, decorador, etc. Padrões de design nos dão uma solução comprovada para problemas existentes e recorrentes. O que eu não aprendi foi que um mecanismo similar existe em um nível superior: padrões de arquitetura de software. Estes são padrões para o layout geral da sua aplicação ou aplicações. Todos eles têm vantagens e desvantagens. E todos eles abordam questões específicas.
Padrão de camadas
O padrão de camadas é provavelmente um dos mais conhecidos padrões de arquitetura de software. Muitos desenvolvedores o usam, sem realmente saber seu nome. A idéia é dividir seu código em “camadas”, onde cada camada tem uma certa responsabilidade e fornece um serviço a uma camada superior.
Não há um número predefinido de camadas, mas estas são as que você vê com mais frequência:
- Camada de apresentação ou UI
- Camada de aplicação
- Camada de negócio ou domínio
- Camada de persistência ou acesso a dados
- Camada de banco de dados
A ideia é que o utilizador inicia um pedaço de código na camada de apresentação executando alguma acção (e.(g. clicando em um botão). A camada de apresentação então chama a camada subjacente, ou seja, a camada da aplicação. Depois vamos para a camada de negócios e finalmente, a camada de persistência armazena tudo no banco de dados. Assim, camadas mais altas dependem e fazem chamadas para as camadas mais baixas.

Você verá variações disso, dependendo da complexidade das aplicações. Algumas aplicações podem omitir a camada da aplicação, enquanto outras adicionam uma camada de caching. É até possível fundir duas camadas em uma só. Por exemplo, o padrão ActiveRecord combina as camadas de negócio e persistência.
Layer Responsibility
Como mencionado, cada camada tem sua própria responsabilidade. A camada de apresentação contém o design gráfico da aplicação, assim como qualquer código para lidar com a interação do usuário. Você não deve adicionar lógica que não seja específica para a interface do usuário nesta camada.
A camada de negócio é onde você coloca os modelos e lógica que é específica para o problema de negócio que você está tentando resolver.
A camada de aplicação fica entre a camada de apresentação e a camada de negócio. Por um lado, ele fornece uma abstração para que a camada de apresentação não precise conhecer a camada de negócio. Em teoria, você poderia mudar a pilha de tecnologia da camada de apresentação sem mudar mais nada na sua aplicação (por exemplo, mudar de WinForms para WPF). Por outro lado, a camada de aplicação fornece um lugar para colocar certa lógica de coordenação que não se encaixa na camada de negócio ou de apresentação.
Finalmente, a camada de persistência contém o código para acessar a camada de banco de dados. A camada de base de dados é a tecnologia subjacente à base de dados (por exemplo, SQL Server, MongoDB). A camada de persistência é o conjunto de códigos para manipular a base de dados: Instruções SQL, detalhes de conexão, etc.
Vantagens
- A maioria dos desenvolvedores estão familiarizados com este padrão.
- Provê uma maneira fácil de escrever uma aplicação bem organizada e testável.
Desvantagens
- Tende a levar a aplicações monolíticas que são difíceis de dividir depois.
- Desenvolvedores frequentemente se encontram escrevendo muito código para passar pelas diferentes camadas, sem adicionar nenhum valor nestas camadas. Se tudo que você está fazendo é escrever uma simples aplicação CRUD, o padrão em camadas pode ser exagerado para você.
Ideal for
- Aplicações padrão da linha de negócios que fazem mais do que apenas operações CRUD
Microkernel
O padrão do microkernel, ou padrão plug-in, é útil quando a sua aplicação tem um conjunto central de responsabilidades e uma coleção de partes intercambiáveis ao lado. O microkernel irá fornecer o ponto de entrada e o fluxo geral da aplicação, sem realmente saber o que os diferentes plug-ins estão fazendo.
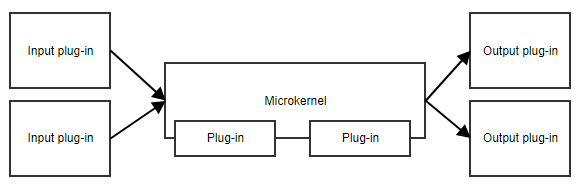
Um exemplo é um agendador de tarefas. O microkernel poderia conter toda a lógica para agendar e acionar tarefas, enquanto os plug-ins contêm tarefas específicas. Desde que os plug-ins adiram a uma API predefinida, o microkernel pode acioná-los sem a necessidade de conhecer os detalhes de implementação.
Um outro exemplo é um workflow. A implementação de um workflow contém conceitos como a ordem dos diferentes passos, avaliando os resultados dos passos, decidindo qual é o próximo passo, etc. A implementação específica dos passos é menos importante para o código central do workflow.
Vantagens
- Este padrão fornece grande flexibilidade e extensibilidade.
- Algumas implementações permitem a adição de plug-ins enquanto a aplicação está em execução.
- Microkernel e plug-ins podem ser desenvolvidos por equipes separadas.
Desvantagens
- Pode ser difícil decidir o que pertence ao microkernel e o que não pertence.
- A API predefinida pode não ser um bom ajuste para plug-ins futuros.
>
Padrão para
- Aplicações que pegam dados de diferentes fontes, transformam esses dados e os escrevem para diferentes destinos
- Aplicações de fluxo de trabalho
- Aplicações de agendamento de tarefas e tarefas
CQRS
CQRS é um acrônimo para Segregação de Comando e Responsabilidade de Consulta. O conceito central deste padrão é que uma aplicação tem operações de leitura e escrita que devem ser totalmente separadas. Isto também significa que o modelo utilizado para operações de escrita (comandos) será diferente dos modelos de leitura (consultas). Além disso, os dados serão armazenados em locais diferentes. Em uma base de dados relacional, isto significa que haverá tabelas para o modelo de comando e tabelas para o modelo lido. Algumas implementações até armazenam os diferentes modelos em bases de dados totalmente diferentes, por exemplo, SQL Server para o modelo de comando e MongoDB para o modelo lido.
Este padrão é frequentemente combinado com o sourcing de eventos, que iremos cobrir abaixo.
Como funciona exactamente? Quando um usuário executa uma ação, a aplicação envia um comando para o serviço de comando. O serviço de comandos recupera quaisquer dados necessários do banco de dados de comandos, faz as manipulações necessárias e armazena esses dados de volta no banco de dados. Depois notifica o serviço de leitura para que o modelo lido possa ser atualizado. Este fluxo pode ser visto abaixo.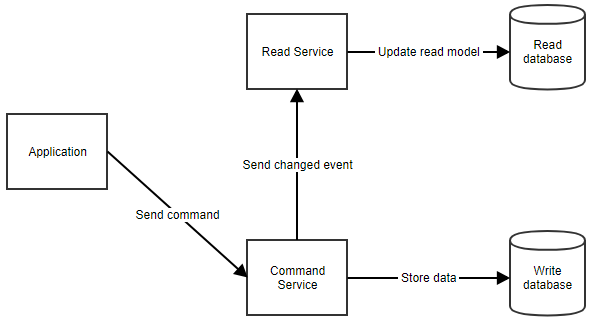
Quando a aplicação precisa mostrar dados para o usuário, ela pode recuperar o modelo lido chamando o serviço de leitura, como mostrado abaixo.
Vantagens
- Os modelos de comando podem focar em lógica de negócios e validação enquanto os modelos lidos podem ser adaptados para cenários específicos.
- Você pode evitar consultas complexas (por exemplo joins in SQL) o que torna as leituras mais performantes.
Desvantagens
- A manutenção do comando e dos modelos lidos em sincronia pode tornar-se complexa.
>
Destino para
- Aplicações que esperam uma grande quantidade de leituras
- Aplicações com domínios complexos
Event Sourcing
Como mencionei acima, o CQRS muitas vezes anda de mãos dadas com o sourcing de eventos. Este é um padrão onde você não armazena o estado atual do seu modelo no banco de dados, mas sim os eventos que aconteceram com o modelo. Assim, quando o nome de um cliente muda, você não armazena o valor em uma coluna “Nome”. Você vai armazenar um evento “NameChanged” com o novo valor (e possivelmente o antigo também).
Quando você precisa recuperar um modelo, você recupera todos os seus eventos armazenados e os aplica novamente em um novo objeto. Chamamos isso de reidratação de um objeto.
Uma analogia da real vida da fonte de suprimentos de eventos é a contabilidade. Quando você adiciona uma despesa, você não modifica o valor do total. Na contabilidade, uma nova linha é adicionada com a operação a ser executada. Se um erro for cometido, você simplesmente adiciona uma nova linha. Para facilitar a sua vida, você poderia calcular o total toda vez que você adiciona uma linha. Este total pode ser considerado como o modelo lido. O exemplo abaixo deve deixar mais claro.

Você pode ver que nós cometemos um erro ao adicionar a Fatura 201805. Em vez de alterar a linha, adicionamos duas novas linhas: primeiro, uma para cancelar a linha errada, depois uma nova e correcta linha. É assim que funciona o sourcing de eventos. Você nunca remove eventos, porque eles aconteceram inegavelmente no passado. Para corrigir situações, nós adicionamos novos eventos.
Ainda, note como nós temos uma célula com o valor total. Isto é simplesmente uma soma de todos os valores nas células acima. No Excel, ele se atualiza automaticamente para que você possa dizer que ele se sincroniza com as outras células. É o modelo lido, fornecendo uma visão fácil para o usuário.
Event sourcing é frequentemente combinado com CQRS porque a reidratação de um objeto pode ter um impacto na performance, especialmente quando há muitos eventos para a instância. Um modelo de leitura rápida pode melhorar significativamente o tempo de resposta da aplicação.
Vantagens
- Este padrão de arquitetura de software pode fornecer um log out of the box de auditoria. Cada evento representa uma manipulação dos dados em um determinado momento.
Desvantagens
- Requer alguma disciplina porque não se pode simplesmente corrigir dados errados com uma simples edição na base de dados.
- Não é uma tarefa trivial alterar a estrutura de um evento. Por exemplo, se você adicionar uma propriedade, o banco de dados ainda contém eventos sem esses dados. Seu código precisará lidar graciosamente com esses dados ausentes.
>
Déal para aplicações que
- Need para publicar eventos em sistemas externos
- Vai ser construído com CQRS
- Dispositivo para aplicações que
- Need para publicar eventos em sistemas externos domínios
- Need um log de auditoria de alterações nos dados
Microservices
Quando você escreve sua aplicação como um conjunto de microserviços, você está na verdade escrevendo várias aplicações que funcionarão juntas. Cada microserviço tem a sua própria responsabilidade e as equipas podem desenvolvê-las independentemente de outros microserviços. A única dependência entre eles é a comunicação. Como os microserviços comunicam uns com os outros, você terá que garantir que as mensagens enviadas entre eles permaneçam compatíveis com o passado. Isto requer alguma coordenação, especialmente quando equipes diferentes são responsáveis por microserviços diferentes.
Um diagrama pode explicar.
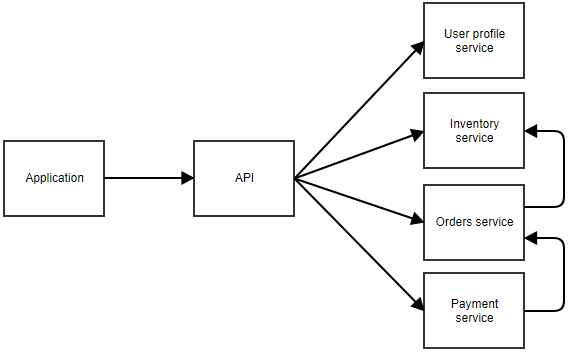 No diagrama acima, a aplicação chama um API central que encaminha a chamada para o microserviço correto. Neste exemplo, existem serviços separados para o perfil do usuário, inventário, pedidos e pagamento. Você pode imaginar que esta é uma aplicação onde o usuário pode pedir algo. Os microserviços separados também podem ligar uns para os outros. Por exemplo, o serviço de pagamento pode notificar o serviço de ordens quando um pagamento for bem sucedido. O serviço de pedidos pode então chamar o serviço de estoque para ajustar o estoque.
No diagrama acima, a aplicação chama um API central que encaminha a chamada para o microserviço correto. Neste exemplo, existem serviços separados para o perfil do usuário, inventário, pedidos e pagamento. Você pode imaginar que esta é uma aplicação onde o usuário pode pedir algo. Os microserviços separados também podem ligar uns para os outros. Por exemplo, o serviço de pagamento pode notificar o serviço de ordens quando um pagamento for bem sucedido. O serviço de pedidos pode então chamar o serviço de estoque para ajustar o estoque.Não há uma regra clara de quão grande pode ser um micro-serviço. No exemplo anterior, o serviço de perfil de usuário pode ser responsável por dados como nome de usuário e senha de um usuário, mas também o endereço residencial, imagem de avatar, favoritos, etc. Também pode ser uma opção para dividir todas essas responsabilidades em microserviços ainda menores.
Vantagens
- Você pode escrever, manter e implementar cada microserviço separadamente.
- Uma arquitetura de microserviços deve ser mais fácil de escalar, pois você pode escalar apenas os microserviços que precisam ser escalados. Não há necessidade de escalar as partes menos usadas da aplicação.
- É mais fácil reescrever partes da aplicação porque elas são menores e menos acopladas a outras partes.
Desvantagens
- Contrariamente ao que você poderia esperar, na verdade é mais fácil escrever um monólito bem estruturado no início e dividi-lo em microserviços mais tarde. Com os microserviços, muitas preocupações extras entram em jogo: comunicação, coordenação, compatibilidade retroativa, registro, etc. Equipes que não possuem a habilidade necessária para escrever um monólito bem estruturado provavelmente terão dificuldade para escrever um bom conjunto de microserviços.
- Uma única ação de um usuário pode passar por vários microserviços. Há mais pontos de falha, e quando algo corre mal, pode levar mais tempo para identificar o problema.
Precisão para:
- Aplicações onde certas partes serão usadas intensivamente e precisam ser escaladas
- Serviços que fornecem funcionalidade a várias outras aplicações
- Aplicações que se tornariam muito complexas se combinadas em um monólito
- Aplicações onde contextos claramente delimitados podem ser definidos
Combine
Explicuguei vários padrões de arquitetura de software, bem como as suas vantagens e desvantagens. Mas há mais padrões do que aqueles que eu expus aqui. Também não é raro combinar vários desses padrões. Eles nem sempre são mutuamente exclusivos. Por exemplo, você poderia ter vários microserviços e ter alguns deles usando o padrão em camadas, enquanto outros usam CQRS e sourcing de eventos.
O importante a lembrar é que não há uma solução que funcione em todos os lugares. Quando fazemos a pergunta sobre qual padrão usar para uma aplicação, a resposta antiga ainda se aplica: “depende.” Você deve ponderar os prós e os contras de uma solução e tomar uma decisão bem informada.