Lorsque je suivais des cours du soir pour devenir programmeur, j’ai appris plusieurs design patterns : singleton, repository, factory, builder, decorator, etc. Les design patterns nous donnent une solution éprouvée à des problèmes existants et récurrents. Ce que je n’ai pas appris, c’est qu’un mécanisme similaire existe à un niveau supérieur : les patrons d’architecture logicielle. Il s’agit de modèles pour l’agencement général de votre ou vos applications. Ils ont tous des avantages et des inconvénients. Et ils abordent tous des problèmes spécifiques.
Patron en couches
Le patron en couches est probablement l’un des patrons d’architecture logicielle les plus connus. De nombreux développeurs l’utilisent, sans vraiment connaître son nom. L’idée est de diviser votre code en « couches », où chaque couche a une certaine responsabilité et fournit un service à une couche supérieure.
Il n’y a pas un nombre prédéfini de couches, mais ce sont celles que vous voyez le plus souvent :
- Couche de présentation ou d’interface utilisateur
- Couche d’application
- Couche métier ou de domaine
- Couche de persistance ou d’accès aux données
- Couche de base de données
L’idée est que l’utilisateur initie un morceau de code dans la couche de présentation en effectuant une action (par ex.g. cliquer sur un bouton). La couche présentation appelle alors la couche sous-jacente, c’est-à-dire la couche application. Ensuite, on passe à la couche métier et enfin, la couche de persistance stocke tout dans la base de données. Ainsi, les couches supérieures dépendent des couches inférieures et leur font des appels.

Vous verrez des variations de ceci, selon la complexité des applications. Certaines applications pourraient omettre la couche applicative, tandis que d’autres ajoutent une couche de mise en cache. Il est même possible de fusionner deux couches en une seule. Par exemple, le patron ActiveRecord combine les couches métier et de persistance.
Responsabilité des couches
Comme mentionné, chaque couche a sa propre responsabilité. La couche de présentation contient la conception graphique de l’application, ainsi que tout code permettant de gérer l’interaction avec l’utilisateur. Vous ne devriez pas ajouter de logique qui n’est pas spécifique à l’interface utilisateur dans cette couche.
La couche métier est l’endroit où vous mettez les modèles et la logique qui est spécifique au problème métier que vous essayez de résoudre.
La couche application se situe entre la couche présentation et la couche métier. D’une part, elle fournit une abstraction pour que la couche de présentation n’ait pas besoin de connaître la couche métier. En théorie, vous pouvez changer la pile technologique de la couche de présentation sans changer quoi que ce soit d’autre dans votre application (par exemple, passer de WinForms à WPF). D’autre part, la couche d’application fournit un endroit pour mettre certaines logiques de coordination qui n’ont pas leur place dans la couche métier ou de présentation.
Enfin, la couche de persistance contient le code pour accéder à la couche de base de données. La couche de base de données est la technologie de base de données sous-jacente (par exemple, SQL Server, MongoDB). La couche de persistance est l’ensemble du code permettant de manipuler la base de données : Instructions SQL, détails de connexion, etc.
Avantages
- La plupart des développeurs sont familiers avec ce pattern.
- Il fournit un moyen facile d’écrire une application bien organisée et testable.
Inconvénients
- Il a tendance à conduire à des applications monolithiques qui sont difficiles à scinder par la suite.
- Les développeurs se retrouvent souvent à écrire beaucoup de code pour passer à travers les différentes couches, sans ajouter aucune valeur dans ces couches. Si tout ce que vous faites est d’écrire une simple application CRUD, le pattern en couches pourrait être exagéré pour vous.
Idéal pour
- Applications standard de ligne d’affaires qui font plus que des opérations CRUD
Microkernel
Le pattern microkernel, ou pattern plug-in, est utile lorsque votre application a un ensemble de responsabilités de base et une collection de parties interchangeables sur le côté. Le micro-noyau fournira le point d’entrée et le flux général de l’application, sans vraiment savoir ce que font les différents plug-ins.
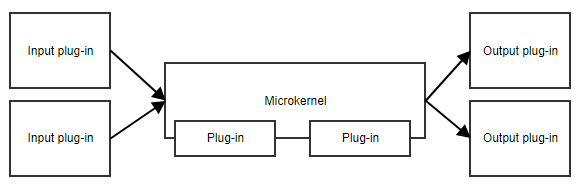
Un exemple est un planificateur de tâches. Le micro-noyau pourrait contenir toute la logique d’ordonnancement et de déclenchement des tâches, tandis que les plug-ins contiennent des tâches spécifiques. Tant que les plug-ins adhèrent à une API prédéfinie, le micro-noyau peut les déclencher sans avoir besoin de connaître les détails de l’implémentation.
Un autre exemple est un workflow. L’implémentation d’un workflow contient des concepts comme l’ordre des différentes étapes, l’évaluation des résultats des étapes, la décision de l’étape suivante, etc. L’implémentation spécifique des étapes est moins importante pour le code central du workflow.
Avantages
- Ce pattern fournit une grande flexibilité et extensibilité.
- Certaines implémentations permettent d’ajouter des plug-ins pendant que l’application fonctionne.
- Le micro-noyau et les plug-ins peuvent être développés par des équipes distinctes.
Inconvénients
- Il peut être difficile de décider ce qui appartient au micro-noyau et ce qui ne l’est pas.
- L’API prédéfinie pourrait ne pas être un bon ajustement pour les futurs plug-ins.
Idéal pour
- Les applications qui prennent des données de différentes sources, transforment ces données et les écrivent vers différentes destinations
- Les applications de workflow
- Les applications de planification de tâches et de travaux
CQRS
CQRS est un acronyme pour Command and Query Responsibility Segregation. Le concept central de ce patron est qu’une application a des opérations de lecture et des opérations d’écriture qui doivent être totalement séparées. Cela signifie également que le modèle utilisé pour les opérations d’écriture (commandes) sera différent des modèles de lecture (requêtes). En outre, les données seront stockées à des endroits différents. Dans une base de données relationnelle, cela signifie qu’il y aura des tables pour le modèle de commande et des tables pour le modèle de lecture. Certaines implémentations stockent même les différents modèles dans des bases de données totalement différentes, par exemple SQL Server pour le modèle de commande et MongoDB pour le modèle de lecture.
Ce modèle est souvent combiné avec l’event sourcing, que nous couvrirons ci-dessous.
Comment cela fonctionne-t-il exactement ? Lorsqu’un utilisateur effectue une action, l’application envoie une commande au service de commande. Le service de commande récupère toutes les données dont il a besoin dans la base de données des commandes, effectue les manipulations nécessaires et les stocke à nouveau dans la base de données. Il notifie ensuite le service de lecture afin que le modèle de lecture puisse être mis à jour. Ce flux peut être vu ci-dessous.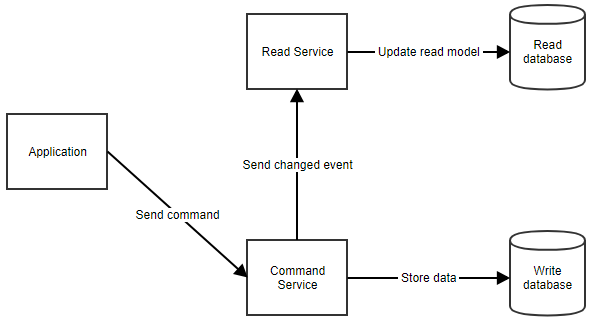
Lorsque l’application doit montrer des données à l’utilisateur, elle peut récupérer le modèle de lecture en appelant le service de lecture, comme indiqué ci-dessous.
Avantages
- Les modèles de commande peuvent se concentrer sur la logique métier et la validation tandis que les modèles de lecture peuvent être adaptés à des scénarios spécifiques.
- Vous pouvez éviter les requêtes complexes (par ex. jointures en SQL), ce qui rend les lectures plus performantes.
Inconvénients
- Maintenir les modèles de commande et de lecture synchronisés peut devenir complexe.
Idéal pour
- Les applications qui attendent une grande quantité de lectures
- Les applications avec des domaines complexes
Event Sourcing
Comme je l’ai mentionné ci-dessus, CQRS va souvent de pair avec l’event sourcing. C’est un modèle où vous ne stockez pas l’état actuel de votre modèle dans la base de données, mais plutôt les événements qui sont arrivés au modèle. Ainsi, lorsque le nom d’un client change, vous ne stockez pas la valeur dans une colonne « Name ». Vous stockerez un événement « NameChanged » avec la nouvelle valeur (et éventuellement l’ancienne aussi).
Lorsque vous devez récupérer un modèle, vous récupérez tous ses événements stockés et les réappliquez sur un nouvel objet. Nous appelons cela réhydrater un objet.
Une analogie réelle du sourcing d’événements est la comptabilité. Lorsque vous ajoutez une dépense, vous ne changez pas la valeur du total. En comptabilité, on ajoute une nouvelle ligne avec l’opération à effectuer. Si une erreur a été commise, vous ajoutez simplement une nouvelle ligne. Pour vous faciliter la vie, vous pourriez calculer le total à chaque fois que vous ajoutez une ligne. Ce total peut être considéré comme le modèle de lecture. L’exemple ci-dessous devrait rendre les choses plus claires.

Vous pouvez voir que nous avons fait une erreur en ajoutant la facture 201805. Au lieu de modifier la ligne, nous avons ajouté deux nouvelles lignes : d’abord, une pour annuler la mauvaise ligne, puis une nouvelle ligne correcte. C’est ainsi que fonctionne le sourcing d’événements. On ne supprime jamais les événements, car ils se sont indéniablement produits dans le passé. Pour corriger les situations, on ajoute de nouveaux événements.
Notez également comment nous avons une cellule avec la valeur totale. Il s’agit simplement d’une somme de toutes les valeurs dans les cellules ci-dessus. Dans Excel, elle se met automatiquement à jour, on pourrait donc dire qu’elle se synchronise avec les autres cellules. C’est le modèle de lecture, fournissant une vue facile pour l’utilisateur.
L’Event sourcing est souvent combiné avec CQRS parce que la réhydratation d’un objet peut avoir un impact sur les performances, surtout quand il y a beaucoup d’événements pour l’instance. Un modèle de lecture rapide peut améliorer de manière significative le temps de réponse de l’application.
Avantages
- Ce modèle d’architecture logicielle peut fournir un journal d’audit hors de la boîte. Chaque événement représente une manipulation des données à un certain moment dans le temps.
Inconvénients
- Il nécessite une certaine discipline parce que vous ne pouvez pas simplement corriger des données erronées avec une simple modification dans la base de données.
- Ce n’est pas une tâche triviale de changer la structure d’un événement. Par exemple, si vous ajoutez une propriété, la base de données contient toujours des événements sans cette donnée. Votre code devra gérer gracieusement ces données manquantes.
Idéal pour les applications qui
- doivent publier des événements vers des systèmes externes
- Vont être construites avec CQRS
- Dont les domaines sont complexes. domaines
- Nécessitent un journal d’audit des modifications apportées aux données
Microservices
Lorsque vous écrivez votre application comme un ensemble de microservices, vous écrivez en fait plusieurs applications qui vont fonctionner ensemble. Chaque microservice a sa propre responsabilité distincte et les équipes peuvent les développer indépendamment des autres microservices. La seule dépendance entre eux est la communication. Comme les microservices communiquent entre eux, vous devrez vous assurer que les messages envoyés entre eux restent rétrocompatibles. Cela nécessite une certaine coordination, surtout lorsque différentes équipes sont responsables de différents microservices.
Un diagramme peut expliquer.
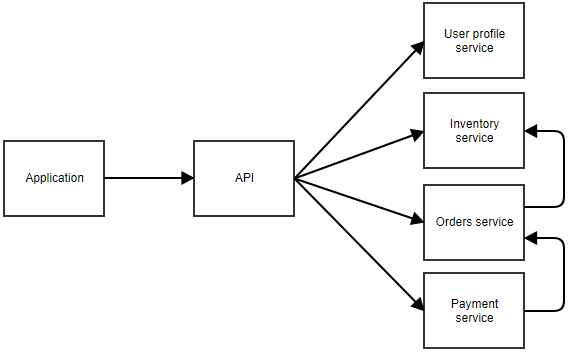 Dans le diagramme ci-dessus, l’application appelle une API centrale qui transmet l’appel au microservice correct. Dans cet exemple, il existe des services distincts pour le profil de l’utilisateur, l’inventaire, les commandes et le paiement. Vous pouvez imaginer qu’il s’agit d’une application où l’utilisateur peut commander quelque chose. Les différents microservices peuvent également s’appeler les uns les autres. Par exemple, le service de paiement peut notifier le service de commande lorsqu’un paiement aboutit. Le service de commandes pourrait alors appeler le service d’inventaire pour ajuster le stock.
Dans le diagramme ci-dessus, l’application appelle une API centrale qui transmet l’appel au microservice correct. Dans cet exemple, il existe des services distincts pour le profil de l’utilisateur, l’inventaire, les commandes et le paiement. Vous pouvez imaginer qu’il s’agit d’une application où l’utilisateur peut commander quelque chose. Les différents microservices peuvent également s’appeler les uns les autres. Par exemple, le service de paiement peut notifier le service de commande lorsqu’un paiement aboutit. Le service de commandes pourrait alors appeler le service d’inventaire pour ajuster le stock.
Il n’y a pas de règle claire sur la taille que peut avoir un microservice. Dans l’exemple précédent, le service de profil utilisateur peut être responsable de données comme le nom d’utilisateur et le mot de passe d’un utilisateur, mais aussi de l’adresse personnelle, de l’image avatar, des favoris, etc. Il pourrait également être une option pour diviser toutes ces responsabilités en microservices encore plus petits.
Avantages
- Vous pouvez écrire, maintenir et déployer chaque microservice séparément.
- Une architecture de microservices devrait être plus facile à mettre à l’échelle, car vous pouvez mettre à l’échelle uniquement les microservices qui doivent être mis à l’échelle. Il n’est pas nécessaire de faire évoluer les pièces moins fréquemment utilisées de l’application.
- Il est plus facile de réécrire des pièces de l’application parce qu’elles sont plus petites et moins couplées à d’autres parties.
Inconvénients
- Contrairement à ce que l’on pourrait penser, il est en fait plus facile d’écrire un monolithe bien structuré au début et de le diviser en microservices plus tard. Avec les microservices, beaucoup de préoccupations supplémentaires entrent en jeu : communication, coordination, rétrocompatibilité, journalisation, etc. Les équipes qui manquent de la compétence nécessaire pour écrire un monolithe bien structuré auront probablement du mal à écrire un bon ensemble de microservices.
- Une seule action d’un utilisateur peut passer par plusieurs microservices. Il y a plus de points d’échec, et quand quelque chose ne va pas, cela peut prendre plus de temps pour localiser le problème.
Idéal pour :
- Applications où certaines parties seront utilisées intensivement et devront être mises à l’échelle
- Services qui fournissent des fonctionnalités à plusieurs autres applications
- Applications qui deviendraient très complexes si elles étaient combinées en un monolithe
- Applications où des contextes délimités clairs peuvent être définis
Combinaison
J’ai expliqué plusieurs modèles d’architecture logicielle, ainsi que leurs avantages et inconvénients. Mais il existe d’autres patterns que ceux que j’ai exposés ici. Il n’est pas rare non plus de combiner plusieurs de ces patterns. Ils ne sont pas toujours mutuellement exclusifs. Par exemple, vous pourriez avoir plusieurs microservices et faire en sorte que certains d’entre eux utilisent le pattern en couches, tandis que d’autres utilisent le CQRS et l’event sourcing.
La chose importante à retenir est qu’il n’y a pas une solution qui fonctionne partout. Lorsque nous posons la question de savoir quel pattern utiliser pour une application, la réponse séculaire s’applique toujours : « ça dépend ». Vous devez peser le pour et le contre d’une solution et prendre une décision en toute connaissance de cause.