- Istnieje wiele metod testowania, czy zmienna ma rozkład normalny. W tym artykule dowiesz się, której z nich użyć!
- 1.1. Wprowadzenie
- 1.2. Interpretacja
- 1.3. Implementacja
- 1.4. Podsumowanie
- 2.1. Wprowadzenie
- 2.2 Interpretacja
- 2.3. Implementacja
- 2.4. Wnioski
- 3.1. Wprowadzenie
- 3.2. Interpretacja
- 3.3. Implementacja
- 3.4. Wnioski
- Test Kołmogorowa Smirnowa
- 4.2. Interpretacja
- 4.3. Implementacja
- 4.4. Conclusion
- Test Lillieforsa
- 5.2. Interpretacja
- 5.3. Implementacja
- 5.4. Conclusion
- Test Shapiro Wilk
- 6.2. Interpretacja
- 6.3. Implementacja
- 6.4. Wnioski
- Wniosek – jakie podejście zastosować!
Istnieje wiele metod testowania, czy zmienna ma rozkład normalny. W tym artykule dowiesz się, której z nich użyć!
1.1. Wprowadzenie
Pierwszą metodą, którą zna prawie każdy, jest histogram. Histogram jest wizualizacją danych, która pokazuje rozkład zmiennej. Daje nam częstotliwość występowania na wartość w zbiorze danych, czyli to, o co chodzi w rozkładach.
Histogram jest świetnym sposobem na szybką wizualizację rozkładu pojedynczej zmiennej.
1.2. Interpretacja
Na poniższym rysunku dwa histogramy przedstawiają rozkład normalny i rozkład nienormalny.
- Po lewej stronie widać bardzo małe odchylenie rozkładu próbki (na szaro) od teoretycznego rozkładu krzywej dzwonowej (czerwona linia).
- Po prawej stronie widzimy całkiem inny kształt histogramu, mówiący nam wprost, że nie jest to rozkład normalny.

1.3. Implementacja
Histogram można łatwo utworzyć w pythonie w następujący sposób:
1.4. Podsumowanie
Histogram to świetny sposób na szybką wizualizację rozkładu pojedynczej zmiennej.
2.1. Wprowadzenie
Box Plot jest kolejną techniką wizualizacji, która może być używana do wykrywania próbek nienormalnych. Box Plot przedstawia 5 liczbowe podsumowanie zmiennej: minimum, pierwszy kwartyl, mediana, trzeci kwartyl i maksimum.
Boxplot jest świetnym sposobem na wizualizację rozkładów wielu zmiennych jednocześnie.
2.2 Interpretacja
Boxplot jest świetną techniką wizualizacji, ponieważ pozwala na umieszczenie wielu boxplotów obok siebie. Posiadanie tego bardzo szybkiego przeglądu zmiennych daje nam wyobrażenie o rozkładzie, a jako „bonus” otrzymujemy pełne 5 liczbowe podsumowanie, które pomoże nam w dalszej analizie.
Powinieneś zwrócić uwagę na dwie rzeczy:
- Czy rozkład jest symetryczny (tak jak rozkład normalny)?
- Czy szerokość (przeciwieństwo punktowości) odpowiada szerokości rozkładu normalnego? Trudno to zobaczyć na wykresie pudełkowym.

2.3. Implementacja
Boxplot może być łatwo zaimplementowany w pythonie w następujący sposób:
2.4. Wnioski
Boxplot to świetny sposób na wizualizację rozkładów wielu zmiennych jednocześnie, ale odchylenie w szerokości/punktowości jest trudne do zidentyfikowania przy użyciu działek pudełkowych.
3.1. Wprowadzenie
W przypadku działek QQ zaczynamy przechodzić do poważniejszych rzeczy, ponieważ wymaga to nieco więcej zrozumienia niż poprzednio opisane metody.
QQ Plot to skrót od Quantile vs Quantile Plot, czyli dokładnie to, co robi: wykreślanie teoretycznych kwantyli względem rzeczywistych kwantyli naszej zmiennej.
Plan QQ pozwala nam zobaczyć odchylenia rozkładu normalnego znacznie lepiej niż na histogramie czy Box Plot.
3.2. Interpretacja
Jeśli nasza zmienna ma rozkład normalny, kwantyle naszej zmiennej muszą być idealnie zgodne z „teoretycznymi” kwantylami normalnymi: prosta linia na QQ Plot mówi nam, że mamy rozkład normalny.
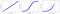
Jak widać na rysunku, punkty na normalnym wykresie QQ Plot podążają za linią prostą, podczas gdy inne rozkłady mocno od niej odbiegają.
- Rozkład jednostajny ma zbyt wiele obserwacji w obu skrajnych punktach (bardzo wysokie i bardzo niskie wartości).
- Rozkład wykładniczy ma zbyt wiele obserwacji przy niższych wartościach, ale zbyt mało przy wyższych wartościach.
W praktyce często widzimy coś mniej wyraźnego, ale o podobnym kształcie. Nadreprezentacja lub niedoreprezentacja w ogonie powinna budzić wątpliwości co do normalności, w takim przypadku należy zastosować jeden z testów hipotez opisanych poniżej.
3.3. Implementacja
Implementacja QQ Plot może być wykonana przy użyciu api statsmodels w pythonie w następujący sposób:
3.4. Wnioski
Wykres QQ Plot pozwala nam zobaczyć odchylenia od rozkładu normalnego znacznie lepiej niż w histogramie czy wykresie pudełkowym.
Test Kołmogorowa Smirnowa
Jeśli wykres QQ Plot i inne techniki wizualizacji nie są rozstrzygające, wnioskowanie statystyczne (testowanie hipotezy) może dać bardziej obiektywną odpowiedź na pytanie, czy nasza zmienna znacząco odbiega od rozkładu normalnego.
Jeśli masz wątpliwości jak i kiedy używać testowania hipotez, oto artykuł, który daje intuicyjne wyjaśnienie testowania hipotez.
Test Kołmogorowa Smirnowa oblicza odległości między rozkładem empirycznym a rozkładem teoretycznym i definiuje statystykę testową jako supremum zbioru tych odległości.
Zaletą tego jest to, że to samo podejście może być użyte do porównania dowolnego rozkładu, niekoniecznie tylko rozkładu normalnego.
Test KS jest dobrze znany, ale nie ma dużej mocy. Może być stosowany dla innych rozkładów niż normalny.
4.2. Interpretacja
Statystyką testową testu KS jest statystyka Kołmogorowa Smirnowa, która podąża za rozkładem Kołmogorowa, jeśli hipoteza zerowa jest prawdziwa.
Jeśli obserwowane dane idealnie podążają za rozkładem normalnym, wartość statystyki KS będzie równa 0. Wartość P służy do rozstrzygnięcia, czy różnica jest wystarczająco duża, aby odrzucić hipotezę zerową:
- Jeśli wartość P testu KS jest większa niż 0,05, zakładamy rozkład normalny
- Jeśli wartość P testu KS jest mniejsza niż 0,05, nie zakładamy rozkładu normalnego
4.3. Implementacja
Test KS w Pythonie przy użyciu Scipy można zaimplementować w następujący sposób. Zwraca on statystykę KS i jej wartość P.
4.4. Conclusion
Test KS jest dobrze znany, ale nie ma zbyt dużej mocy. Oznacza to, że do odrzucenia hipotezy zerowej potrzebna jest duża liczba obserwacji. Jest on również wrażliwy na wartości odstające. Z drugiej strony, może być stosowany do innych typów rozkładów.
Test Lillieforsa
Test Lillieforsa jest silnie oparty na teście KS. Różnica polega na tym, że w teście Lillieforsa przyjmuje się, że średnia i wariancja rozkładu populacji są oszacowane, a nie wstępnie określone przez użytkownika.
Z tego powodu test Lillieforsa wykorzystuje rozkład Lillieforsa, a nie rozkład Kołmogorowa.
Niestety dla testu Lillieforsa, jego moc jest wciąż niższa niż testu Shapiro Wilka.
5.2. Interpretacja
- Jeśli wartość P testu Lillieforsa jest większa niż 0,05, zakładamy rozkład normalny
- Jeśli wartość P testu Lillieforsa jest mniejsza niż 0,05, nie zakładamy rozkładu normalnego
5.3. Implementacja
Aplikacja testu Lillieforsa w statsmodels zwróci wartość statystyki testowej Lillieforsa oraz P-Value w następujący sposób.
Uwaga: w implementacji statsmodels, P-Values niższe niż 0.001 są podawane jako 0,001, a P-Values wyższe niż 0,2 są podawane jako 0,2.
5.4. Conclusion
Although Lilliefors is an improvement to the KS test it’s still lower than the Shapiro Wilk test.
Test Shapiro Wilk
Test Shapiro Wilk jest najpotężniejszym testem podczas testowania dla rozkładu normalnego. Został on opracowany specjalnie dla rozkładu normalnego i nie może być używany do testowania przeciwko innym rozkładom, jak na przykład test KS.
Test Shapiro Wilka jest najpotężniejszym testem podczas testowania dla rozkładu normalnego.
6.2. Interpretacja
- Jeśli wartość P testu Shapiro Wilka jest większa niż 0,05, zakładamy rozkład normalny
- Jeśli wartość P testu Shapiro Wilka jest mniejsza niż 0,05, nie zakładamy rozkładu normalnego
6.3. Implementacja
Test Shapiro Wilka można zaimplementować w następujący sposób. Zwróci on statystykę testową o nazwie W oraz wartość P.
Uwaga: dla N > 5000 statystyka testowa W jest dokładna, ale wartość p może nie być.
6.4. Wnioski
Test Shapiro Wilka jest najpotężniejszym testem podczas testowania dla rozkładu normalnego. Powinieneś zdecydowanie użyć tego testu.
Wniosek – jakie podejście zastosować!
Dla szybkiej i wizualnej identyfikacji rozkładu normalnego, użyj wykresu QQ, jeśli masz tylko jedną zmienną do obejrzenia i Box Plot, jeśli masz wiele. Użyj histogramu, jeśli musisz przedstawić swoje wyniki niestatystycznej publiczności.
Jako testu statystycznego do potwierdzenia hipotezy, użyj testu Shapiro Wilka. Jest to najpotężniejszy test, który powinien być decydującym argumentem.
Przy testowaniu względem innych rozkładów nie możesz użyć testu Shapiro Wilka i powinieneś użyć np. testu Andersona-Darlinga lub testu KS.
.