Kiedy uczęszczałem do szkoły wieczorowej, aby zostać programistą, nauczyłem się kilku wzorców projektowych: singleton, repozytorium, fabryka, konstruktor, dekorator itp. Wzorce projektowe dają nam sprawdzone rozwiązania dla istniejących i powtarzających się problemów. To, czego się nie dowiedziałem, to fakt, że podobny mechanizm istnieje na wyższym poziomie: wzorce architektury oprogramowania. Są to wzorce dla ogólnego układu Twojej aplikacji lub aplikacji. Wszystkie mają wady i zalety. I wszystkie odnoszą się do konkretnych problemów.
Wzorzec warstwowy
Wzorzec warstwowy jest prawdopodobnie jednym z najbardziej znanych wzorców architektury oprogramowania. Wielu programistów używa go, nie znając tak naprawdę jego nazwy. Ideą jest podzielenie kodu na „warstwy”, gdzie każda warstwa ma pewną odpowiedzialność i dostarcza usługi do wyższej warstwy.
Nie ma predefiniowanej liczby warstw, ale są to te, które widzisz najczęściej:
- Prezentacja lub warstwa UI
- Warstwa aplikacji
- Warstwa biznesowa lub domenowa
- Warstwa trwałości lub dostępu do danych
- Warstwa bazy danych
Pomysł jest taki, że użytkownik inicjuje kawałek kodu w warstwie prezentacji poprzez wykonanie jakiejś akcji (np.np. klikając przycisk). Następnie warstwa prezentacji wywołuje warstwę bazową, czyli warstwę aplikacji. Następnie przechodzimy do warstwy biznesowej i w końcu, warstwa trwałości przechowuje wszystko w bazie danych. Tak więc wyższe warstwy są zależne od niższych warstw i do nich dzwonią.

Zobaczysz różne warianty tego, w zależności od złożoności aplikacji. Niektóre aplikacje mogą pominąć warstwę aplikacji, podczas gdy inne dodają warstwę buforowania. Możliwe jest nawet połączenie dwóch warstw w jedną. Na przykład wzorzec ActiveRecord łączy warstwy biznesową i trwałości.
Odpowiedzialność warstw
Jak wspomniano, każda warstwa ma swoją własną odpowiedzialność. Warstwa prezentacji zawiera projekt graficzny aplikacji, a także wszelki kod do obsługi interakcji z użytkownikiem. Nie powinieneś dodawać logiki, która nie jest specyficzna dla interfejsu użytkownika w tej warstwie.
Warstwa biznesowa jest miejscem, w którym umieszczasz modele i logikę, która jest specyficzna dla problemu biznesowego, który próbujesz rozwiązać.
Warstwa aplikacji siedzi pomiędzy warstwą prezentacji a warstwą biznesową. Z jednej strony zapewnia ona abstrakcję, dzięki której warstwa prezentacji nie musi znać warstwy biznesowej. W teorii można zmienić stos technologiczny warstwy prezentacji bez zmiany czegokolwiek innego w aplikacji (np. zmiana z WinForms na WPF). Z drugiej strony, warstwa aplikacji zapewnia miejsce do umieszczenia pewnej logiki koordynacyjnej, która nie pasuje do warstwy biznesowej lub prezentacyjnej.
Wreszcie, warstwa trwałości zawiera kod dostępu do warstwy bazy danych. Warstwa bazy danych to podstawowa technologia bazodanowa (np. SQL Server, MongoDB). Warstwa persystencji jest zestawem kodu do manipulowania bazą danych: instrukcje SQL, szczegóły połączenia itp.
Zalety
- Większość programistów zna ten wzorzec.
- Zapewnia on łatwy sposób pisania dobrze zorganizowanej i testowalnej aplikacji.
Wady
- Ma tendencję do tworzenia monolitycznych aplikacji, które trudno potem podzielić.
- Deweloperzy często przekonują się, że piszą dużo kodu, aby przejść przez różne warstwy, nie dodając do nich żadnej wartości. Jeśli wszystko, co robisz, to pisanie prostej aplikacji CRUD, wzór warstwowy może być dla ciebie overkill.
Idealny dla
- Standardowych aplikacji biznesowych, które wykonują więcej niż tylko operacje CRUD
Mikrokernel
Wzorzec mikrokernela, lub wzorzec wtyczki, jest przydatny, gdy twoja aplikacja ma podstawowy zestaw obowiązków i kolekcję wymiennych części na boku. Mikrokernel zapewni punkt wejścia i ogólny przepływ aplikacji, nie wiedząc tak naprawdę, co robią różne wtyczki.
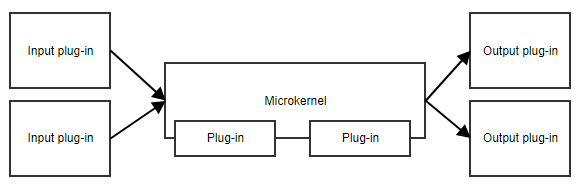
Przykładem jest harmonogram zadań. Mikrokernel mógłby zawierać całą logikę do planowania i wyzwalania zadań, podczas gdy wtyczki zawierają konkretne zadania. Tak długo jak wtyczki stosują się do predefiniowanego API, mikrokernel może je wyzwalać bez potrzeby znajomości szczegółów implementacji.
Innym przykładem jest przepływ pracy. Implementacja przepływu pracy zawiera koncepcje takie jak kolejność różnych kroków, ocenianie wyników kroków, decydowanie o tym, jaki jest następny krok, itp. Konkretna implementacja kroków jest mniej istotna dla kodu rdzenia przepływu pracy.
Wady
- Wzorzec ten zapewnia dużą elastyczność i rozszerzalność.
- Niektóre implementacje pozwalają na dodawanie wtyczek podczas działania aplikacji.
- Mikrokernel i wtyczki mogą być rozwijane przez oddzielne zespoły.
Wady
- Może być trudno zdecydować, co należy do mikrokernela, a co nie.
- Predefiniowany interfejs API może nie być dobrym rozwiązaniem dla przyszłych wtyczek.
Idealne dla
- Aplikacji, które pobierają dane z różnych źródeł, przekształcają te dane i zapisują je w różnych miejscach docelowych
- Aplikacji przepływu pracy
- Aplikacji harmonogramowania zadań i pracy
CQRS
CQRS jest akronimem od Command and Query Responsibility Segregation. Centralną koncepcją tego wzorca jest to, że aplikacja ma operacje odczytu i operacje zapisu, które muszą być całkowicie oddzielone. Oznacza to również, że model używany do operacji zapisu (komendy) będzie różnił się od modeli odczytu (zapytania). Ponadto, dane będą przechowywane w różnych lokalizacjach. W relacyjnej bazie danych oznacza to, że będą istniały tabele dla modelu poleceń i tabele dla modelu odczytu. Niektóre implementacje przechowują nawet różne modele w całkowicie różnych bazach danych, np. SQL Server dla modelu poleceń i MongoDB dla modelu odczytu.
Ten wzorzec jest często łączony z pozyskiwaniem zdarzeń, które omówimy poniżej.
Jak to dokładnie działa? Kiedy użytkownik wykonuje akcję, aplikacja wysyła polecenie do usługi poleceń. Usługa poleceń pobiera wszelkie dane, których potrzebuje z bazy danych poleceń, dokonuje niezbędnych manipulacji i zapisuje je z powrotem w bazie danych. Następnie powiadamia usługę odczytu, aby model odczytu mógł zostać zaktualizowany. Ten przepływ można zobaczyć poniżej.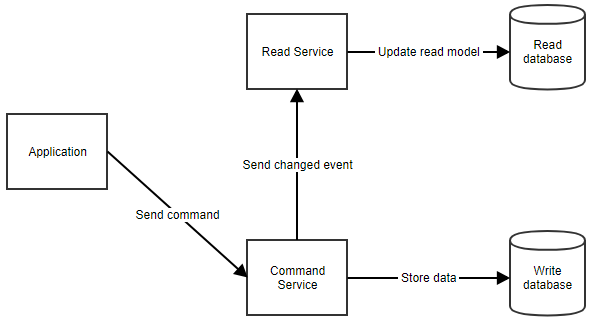
Gdy aplikacja musi pokazać dane użytkownikowi, może pobrać model odczytu, wywołując usługę odczytu, jak pokazano poniżej.
Zalety
- Modele poleceń mogą koncentrować się na logice biznesowej i walidacji, podczas gdy modele odczytu mogą być dostosowane do konkretnych scenariuszy.
- Można uniknąć złożonych zapytań (np. złączenia w SQL), co sprawia, że odczyty są bardziej wydajne.
Wady
- Utrzymywanie modeli poleceń i odczytu w synchronizacji może stać się skomplikowane.
Idealne dla
- Aplikacji, które oczekują dużej ilości odczytów
- Aplikacji ze złożonymi domenami
Event Sourcing
Jak wspomniałem powyżej, CQRS często idzie w parze z event sourcingiem. Jest to wzorzec, w którym nie przechowujesz aktualnego stanu swojego modelu w bazie danych, ale raczej zdarzenia, które miały miejsce w modelu. Więc kiedy nazwa klienta się zmieni, nie będziesz przechowywał wartości w kolumnie „Name”. Zapiszesz zdarzenie „NameChanged” z nową wartością (i być może również starą).
Gdy potrzebujesz odzyskać model, pobierasz wszystkie jego przechowywane zdarzenia i ponownie stosujesz je na nowym obiekcie. Nazywamy to nawadnianiem obiektu.
Realną analogią do pozyskiwania zdarzeń jest księgowość. Kiedy dodajesz wydatek, nie zmieniasz wartości sumy. W księgowości dodaje się nowy wiersz z operacją, która ma być wykonana. Jeśli został popełniony błąd, po prostu dodajesz nową linię. Aby ułatwić sobie życie, możesz obliczać sumę za każdym razem, gdy dodajesz wiersz. Ta suma może być traktowana jako model odczytu. Poniższy przykład powinien sprawić, że będzie to bardziej jasne.

Widzisz, że popełniliśmy błąd podczas dodawania Faktury 201805. Zamiast zmieniać wiersz, dodaliśmy dwa nowe wiersze: najpierw jeden, aby anulować błędny wiersz, a następnie nowy i poprawny wiersz. Tak właśnie działa event sourcing. Nigdy nie usuwa się zdarzeń, ponieważ niezaprzeczalnie miały one miejsce w przeszłości. Aby poprawić sytuacje, dodajemy nowe zdarzenia.
Zauważ również, jak mamy komórkę z wartością całkowitą. Jest to po prostu suma wszystkich wartości w komórkach powyżej. W Excelu jest ona automatycznie aktualizowana, więc można powiedzieć, że synchronizuje się z innymi komórkami. Jest to model odczytu, zapewniający łatwy widok dla użytkownika.
Event sourcing jest często łączony z CQRS, ponieważ nawadnianie obiektu może mieć wpływ na wydajność, zwłaszcza gdy istnieje wiele zdarzeń dla instancji. Model szybkiego odczytu może znacznie poprawić czas odpowiedzi aplikacji.
Wady
- Ten wzorzec architektury oprogramowania może zapewnić dziennik audytu po wyjęciu z pudełka. Każde zdarzenie reprezentuje manipulację danymi w określonym punkcie czasu.
Wady
- Wymaga pewnej dyscypliny, ponieważ nie można po prostu naprawić błędnych danych za pomocą prostej edycji w bazie danych.
- Zmiana struktury zdarzenia nie jest trywialnym zadaniem. Na przykład, jeśli dodasz właściwość, baza danych nadal zawiera zdarzenia bez tych danych. Twój kod będzie musiał łaskawie obsłużyć te brakujące dane.
Idealne dla aplikacji, które
- Muszą publikować zdarzenia do zewnętrznych systemów
- Będą budowane z CQRS
- Mają złożone domeny
- Potrzebują dziennika audytu zmian danych
Mikroserwisy
Gdy piszesz swoją aplikację jako zestaw mikroserwisów, to tak naprawdę piszesz wiele aplikacji, które będą ze sobą współpracować. Każda mikroserwis ma swoją własną, odrębną odpowiedzialność i zespoły mogą je rozwijać niezależnie od innych mikroserwisów. Jedyną zależnością pomiędzy nimi jest komunikacja. Ponieważ mikroserwisy komunikują się ze sobą, będziesz musiał upewnić się, że wiadomości wysyłane między nimi pozostają kompatybilne wstecz. Wymaga to pewnej koordynacji, zwłaszcza gdy różne zespoły są odpowiedzialne za różne mikroserwisy.
Diagram może wyjaśnić.
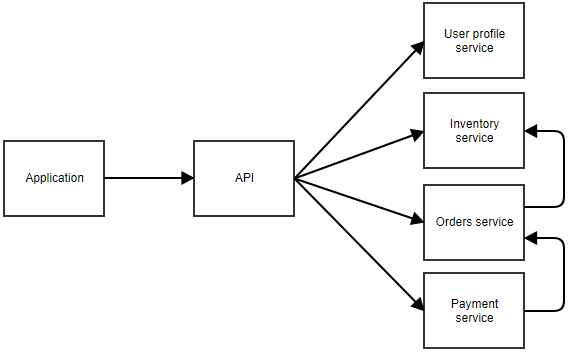 Na powyższym diagramie aplikacja wywołuje centralne API, które przekazuje wywołanie do właściwej mikroserwisu. W tym przykładzie, istnieją oddzielne usługi dla profilu użytkownika, zapasów, zamówień i płatności. Można sobie wyobrazić, że jest to aplikacja, w której użytkownik może coś zamówić. Oddzielne mikroserwisy mogą również wywoływać siebie nawzajem. Na przykład, usługa płatności może powiadomić usługę zamówień, gdy płatność się powiedzie. Usługa zamówień mogłaby wtedy wywołać usługę inwentaryzacji w celu dostosowania zapasów.
Na powyższym diagramie aplikacja wywołuje centralne API, które przekazuje wywołanie do właściwej mikroserwisu. W tym przykładzie, istnieją oddzielne usługi dla profilu użytkownika, zapasów, zamówień i płatności. Można sobie wyobrazić, że jest to aplikacja, w której użytkownik może coś zamówić. Oddzielne mikroserwisy mogą również wywoływać siebie nawzajem. Na przykład, usługa płatności może powiadomić usługę zamówień, gdy płatność się powiedzie. Usługa zamówień mogłaby wtedy wywołać usługę inwentaryzacji w celu dostosowania zapasów.
Nie ma jasnej reguły, jak duża może być mikroserwis. W poprzednim przykładzie usługa profilu użytkownika może być odpowiedzialna za dane takie jak nazwa użytkownika i hasło użytkownika, ale także adres domowy, obraz awatara, ulubione itp. Opcją może być również podzielenie tych wszystkich obowiązków na jeszcze mniejsze mikroserwisy.
Zalety
- Możesz pisać, utrzymywać i wdrażać każdy mikroserwis osobno.
- Architektura mikroserwisów powinna być łatwiejsza do skalowania, ponieważ możesz skalować tylko te mikroserwisy, które wymagają skalowania. Nie ma potrzeby skalowania rzadziej używanych części aplikacji.
- Łatwiej jest przepisywać części aplikacji, ponieważ są one mniejsze i mniej sprzężone z innymi częściami.
Wady
- Wbrew temu, czego można by się spodziewać, w rzeczywistości łatwiej jest napisać dobrze zorganizowany monolit na początku i podzielić go na mikroserwisy później. W przypadku mikroserwisów w grę wchodzi wiele dodatkowych problemów: komunikacja, koordynacja, kompatybilność wsteczna, logowanie itp. Zespoły, którym brakuje umiejętności niezbędnych do napisania dobrze skonstruowanego monolitu, prawdopodobnie będą miały trudności z napisaniem dobrego zestawu mikroserwisów.
- Pojedyncza akcja użytkownika może przechodzić przez wiele mikroserwisów. Istnieje więcej punktów awarii, a kiedy coś pójdzie nie tak, zidentyfikowanie problemu może zająć więcej czasu.
Idealne dla:
- Aplikacji, w których pewne części będą używane intensywnie i muszą być skalowane
- Usług, które zapewniają funkcjonalność kilku innym aplikacjom
- Aplikacji, które stałyby się bardzo złożone, gdyby połączyć je w jeden monolit
- Aplikacji, w których można zdefiniować wyraźne konteksty ograniczone
Combine
Wyjaśniłem kilka wzorców architektury oprogramowania, jak również ich zalety i wady. Ale istnieje więcej wzorców niż te, które tu przedstawiłem. Nie jest też rzadkością łączenie kilku z tych wzorców. Nie zawsze są one wzajemnie wykluczające się. Na przykład, można mieć kilka mikroserwisów i niektóre z nich używają wzorca warstwowego, podczas gdy inne używają CQRS i event sourcing.
Ważną rzeczą do zapamiętania jest to, że nie ma jednego rozwiązania, które działa wszędzie. Kiedy zadajemy pytanie, którego wzorca użyć dla danej aplikacji, wciąż obowiązuje odwieczna odpowiedź: „to zależy”. Powinieneś zważyć na plusy i minusy danego rozwiązania i podjąć dobrze poinformowaną decyzję.
.