Denna handledning visar hur du enkelt kan skriva dina egna Bash-skript på Linux.
Som systemadministratör är det ganska troligt att du utför repetitiva uppgifter som skulle kunna automatiseras.
Troligt nog för dig finns det ett programmeringsspråk som kan användas på Linux för att skriva skript : programmeringsspråket Bash.
Med hjälp av Bash kan du schemalägga säkerhetskopieringar av hela systemet genom att specificera så många kommandon som du vill i Bash-skript.
Du kan också ha anpassade skript som skapar och raderar användare och tar bort deras tillhörande filer.
Med Bash kan du också ha skript som körs och dumpar användbar prestandamätning till en fil eller databas.
Bash är ett mycket kraftfullt programmeringsspråk för systemadministratörer.
I dagens handledning kommer vi att lära oss allt det grundläggande som det finns att veta om Bash : hur man skapar och kör skript, hur man använder variabler och shell built-ins effektivt.
Innehållsförteckning
- Vad du kommer att lära dig
- För att komma igång med Bash
- Historia om Bash
- Programmeringsspråket Bash
- Skapa och kör Bash-skript
- Specificera skalet med hjälp av shebang
- Exekvera Bash-skript
- Specificera skaltolk
- Specificera sökvägen till skriptet
- Lägga till skriptet till PATH
- Shell built-ins explained
- Användning av Bash-variabler
- Exekvering av kommandon inom skript
- Förståelse av avslutningsstatusar
- Manipulera villkor i Bash
- Praktikfall : Kontrollera om användaren är root
- Slutsats
Vad du kommer att lära dig
Om du läser den här handledningen till slutet kommer du att lära dig följande begrepp om Bash
- Hur man skapar och kör Bash-skript med hjälp av kommandoraden;
- Hur shebang är och hur det används av Linux för skript;
- Vad shell built-ins är och hur de skiljer sig från vanliga systemprogram;
- Hur man använder Bash-variabler och vad speciella variabler är;
- Hur man använder Bash kommandosubstitution;
- Hur man använder enkla IF-satser i Bash;
Som du kan se är det här ett ganska långt program, så utan vidare ska vi börja med att se hur du kan skapa och köra Bash-skript.
För att komma igång med Bash
För att utfärda några kommandon ska vi ta ett kort ord om Bash och Shell gemensamma historier.
Historia om Bash
Den första versionen av Bash-skalet släpptes 1989 av Brian Fox och det kommer som en öppen källkods-implementation av Unix-skalet.
På den tiden, när Unix-system började uppstå, använde sådana system standard Unix-shells som hette Bourne-shells.

I Unix’ tidiga dagar var de system som utvecklades av företag som MIT eller Bell Labs inte fria och de var inte heller öppna källkoder.
Även om dokumentation tillhandahölls för dessa verktyg blev det en prioritet för GNU-initiativet (lett av Richard Stallman) att ha en egen version av Unix Shell.
Sex år efter tillkännagivandet av GNU-projektet föddes skalet Bash (Bourne-Again Shell) med ännu fler funktioner än det ursprungliga Bourne shell.
Programmeringsspråket Bash
När man arbetar med ett Unix-liknande system som Linux har Bash vanligtvis två betydelser :
- Bash är en kommandoradstolkare eller med andra ord ett Unix-skal. Det innebär att när du öppnar en terminal kommer du att möta ett Unix-skal som oftast är ett Bash-skal.
När du skriver kommandon direkt i terminalen tolkas kommandona av skalet, de utförs med hjälp av systemanrop och returvärden ges tillbaka till slutanvändaren.
Om du inte är säker på vilken tolk du för närvarande använder, anger miljövariabeln SHELL vilket skal du för närvarande använder.
$ printenv SHELL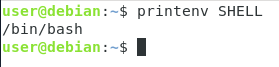
Som du kan se använder vi i det här fallet korrekt Bash-kommandotolken för att arbeta.
Det är viktigt att notera att även om termer som ”Bash scripting” och ”Shell scripting” används omväxlande, så kanske de faktiskt inte beskriver samma sak beroende på din distribution.
Vissa nyare distributioner (t.ex. Debian 10) har symboliska länkar från det ursprungliga Bourne-skalet (som heter sh) till sina egna skalimplementationer (i det här fallet Dash eller Debians Almquist-skal)

- Bash beskriver också ett kommandoradsspråk och det kallas också Bash-språket. Bash exponerar en uppsättning operatörer och operander som kan användas för att få vissa grundläggande funktioner som piping eller att utföra flera kommandon samtidigt.
När man utför grundläggande piping är man van att arbeta med symbolen ”|”. Denna symbol är en del av kommandoradsspråket Bash.
Samma logik gäller för symbolen ”&&” som utför det andra kommandot om, och endast om, det första kommandot lyckades.
$ command1 && command2Skapa och kör Bash-skript
Nu när du har en viss bakgrund om Bash-skalet och kommandoradsspråket Bash kan vi börja med att skapa och köra enkla Bash-skript.
För att skapa ditt första Bash-skript skapar du helt enkelt en fil med namnet ”script.sh”.
Som du säkert redan har märkt använder vi fortfarande tillägget ”sh” som hänvisar till det ursprungliga Bourne-skalet (även betecknat som sh).
$ touch script.shNu räcker det inte med att skapa en fil som slutar med tillägget ”sh” för att ditt skript ska betraktas som ett skalskript.
Du kan faktiskt se att din fil ännu inte betraktas som ett skalskript genom att köra kommandot file.
$ file script.sh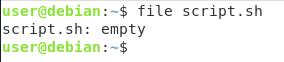
Som du kan se här, är din fil endast beskriven en enkel tom fil.
För att din fil ska beskrivas som en fil med ett skalskript måste du ange shebang-linjen i början av din fil.
Specificera skalet med hjälp av shebang
Om du har använt Linux under en längre tid är det mycket troligt att du redan har stött på shebang-linjen i början av din fil.
Shebang, en förkortning av ”Hash + ”Bang”, är en enradig rad som sätts i början av skalskript för att ange vilket skal som ska användas för att tolka skriptet.
#!/bin/<shell>I vårt fall vill vi arbeta med Bash-skript. Med andra ord vill vi att våra skript ska tolkas av en Bash-tolkare.
För att bestämma sökvägen till tolkaren kan du använda kommandot ”which”.
$ which bash/bin/bashNär du nu vet sökvägen till din tolkare redigerar du din skriptfil och lägger till shebang-linjen i början av filen.
#!/bin/bashNu när du har lagt till denna rad i början av din fil utför du kommandot ”file” på nytt för att se skillnaden.

Som du kan se är utmatningen något annorlunda : den här gången ses ditt manuskript som ett ”Bourne-Again shell script” och ännu viktigare som en körbar fil.
Så vad skulle hända om du inte specificerade shebang-linjen i början av skriptet.
När du inte specificerar shebang-linjen körs skriptet med hjälp av det aktuella skalet som används för att starta kommandot execute.
Nu när du vet hur man skapar Bash-skript, låt oss se hur du kan exekvera dem.
Exekvera Bash-skript
För att exekvera Bash-skript på Linux har du i huvudsak två alternativ :
- Där du anger den skaltolk som du vill använda och skriptfilen;
- Där du använder sökvägen till skriptfilen
Specificera skaltolk
Den första metoden är ganska okomplicerad.
För att exekvera ditt bash-skript ska du själv ange vilken tolk du vill använda.
$ bash <script>$ /bin/bash <script>Om vi använder exemplet som vi använde tidigare skulle detta ge oss följande utdata.
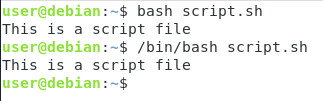
Som du kan se kräver den här metoden inte ens exekveringsrättigheterna på filen, du behöver bara kunna använda den körbara bash-filen.
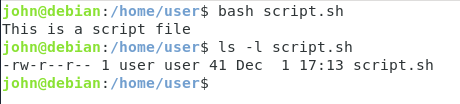
Som du kan se kan jag, när jag är inloggad som en annan användare, utan exekveringsrättigheter, fortfarande exekvera det här skriptet.
Detta är en viktig anmärkning eftersom du kanske vill lagra dina skriptfiler i skyddade kataloger (som bara du har åtkomst till) för att förhindra att andra användare exekverar dina filer.
Specificera sökvägen till skriptet
Det andra sättet att exekvera bash-skript är att specificera sökvägen till filen.
För att kunna använda den här metoden måste filen ha exekveringsrättigheter.
Först använder du kommandot ”chmod” för att ställa in exekveringsrättigheter för den aktuella användaren.
$ chmod u+x <script>
Som du kan se är färgen på filen helt annorlunda : din nuvarande terminal markerar körbara filer med specifika färger, i det här fallet den gröna färgen.
Nu när skriptet är körbart kan du exekvera det genom att ange den relativa eller absoluta sökvägen till skriptet.
Med hjälp av en fil med namnet ”script.sh” som finns i min nuvarande arbetskatalog kan skriptet exekveras genom att köra
$ ./script.shOm du befinner dig i en annan katalog måste du ange den absoluta sökvägen till skriptfilen.
$ /home/user/script.sh
Som du antagligen insett vid det här laget är den här metoden inte särskilt praktisk om du måste ange sökvägen till skriptet varje gång.
Troligt nog för dig finns det ett sätt att exekvera ditt skript genom att helt enkelt skriva filnamnet i kommandoraden.
Lägga till skriptet till PATH
Det behövs inte tillägget ”.sh” för att ett skript ska betraktas som en skriptfil.
För enkelhetens skull kommer vi att byta namn på den befintliga ”script.sh”-filen till ”script”.
För att byta namn på filer i Linux använder du helt enkelt kommandot ”mv” och anger käll- och destinationsmålen.
$ mv script.sh scriptTänk om du vill exekvera ditt skript genom att skriva ”script”?
För att göra det måste du lägga till sökvägen till ditt skript i miljövariabeln PATH.
För att skriva ut det aktuella värdet för din PATH-miljövariabel använder du ”printenv” med argumentet ”PATH”.
$ printenv PATHFör att uppdatera PATH i din nuvarande arbetsmiljö redigerar du miljövariabeln PATH med följande syntax:
$ export PATH="<path_to_script>:$PATH"Nu kommer kommandot ”script” som du just definierat att vara direkt tillgängligt utan att ange några sökvägar : du kan starta det som alla andra kommandon.
Notera : om du vill göra dina ändringar permanenta, följ dessa steg för att uppdatera din PATH-variabel på rätt sätt.
Shell built-ins explained
För att kunna deklarera några variabler i ditt shell-skript är det viktigt för dig att känna till shell built-ins.
När du arbetar med Bash-skalet utför du för det mesta ”program”.
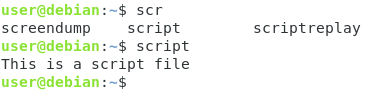
Exempel på program är ”ls”, ”fdisk” eller ”mkdir”. Hjälp för dessa kommandon kan hittas genom att använda kommandot ”man” som är en förkortning för ”manual”.
Har du dock någonsin försökt läsa dokumentationen för kommandot ”source”?
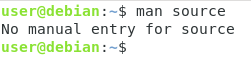
Du skulle inte kunna läsa dokumentationen med hjälp av ”man” eftersom kommandot ”source” är en funktion som är inbyggd i skalet.
För att kunna läsa dokumentationen för inbyggda funktioner i skalet måste du använda kommandot ”help”.
$ help <command>
Listan över inbyggda skalfunktioner är ganska omfattande men här är en skärmdump av varje inbyggt bash-kommando som du kan hitta på Ubuntusystem.

Användning av Bash-variabler
Nu när du känner till Bash built-ins är det dags för dig att börja skriva dina egna Bash-skript.
Som en påminnelse kan de kommandon som skrivs in i din terminal användas i ett Bash-skript på exakt samma sätt.
Om du till exempel vill ha ett skript som helt enkelt utför kommandot ”ls -l” redigerar du helt enkelt ditt skript, lägger till shebang-linjen och kommandot.
#!/bin/bash# This simple script executes the ls commandls -l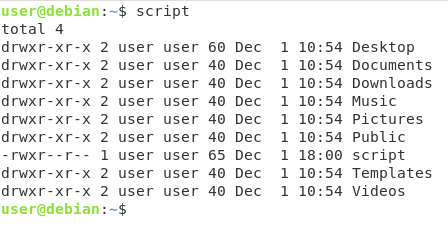
Nu, hur skulle det vara om du ville ha Bash-variabler?
Bashvariabler är enkla programvariabler som kan lagra en mängd olika indata.
För att deklarera en Bashvariabel anger du helt enkelt namnet på variabeln och dess värde åtskilda av ett likhetstecken.
VAR=valueFör att kunna använda innehållet i din Bashvariabel i ditt skript använder du ”$” och lägger till namnet på din variabel.
echo $VAR
Även om du kan använda den här syntaxen för att ha variabelns värde kan du också använda notationen ”parentes”.
echo ${VAR}Med hjälp av den här syntaxen kan variabler kombineras tillsammans.
Om du till exempel har två Bash-variabler som heter VAR1 och VAR2 kan du få dem båda utskrivna med hjälp av följande syntax
echo "${VAR1}${VAR2}"
Exekvering av kommandon inom skript
För att kunna exekvera kommandon inom Bash-skript måste du använda kommandosubstitution.
Kommandosubstitution är en teknik som används i Bash-skalor för att lagra resultatet av ett kommando i en variabel.
För att ersätta ett kommando i Bash använder du dollartecknet och omsluter ditt kommando inom parentes.
VAR=$(command)För att till exempel få resultatet av antalet filer i din aktuella katalog skulle du skriva
#!/bin/bashNUMBER=$(ls -l | wc -l)echo "${NUMBER} files in this directory!"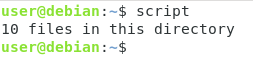
Som du kan se är kommandosubstitutionen ganska praktisk eftersom den kan användas för att dynamiskt exekvera kommandon i ett skalskript och returnera värdet till användaren.
När vi talar om att returnera resultat till slutanvändaren, hur hanterar du skript som inte avslutas korrekt?
Vad händer om ett kommando i skriptet inte utfördes korrekt?
Förståelse av avslutningsstatusar
När du kör ett skript, även om du inte returnerar något värde, returnerar skriptet alltid vad vi kallar ”en avslutningsstatus”.
En avslutningsstatus i Bash-skript indikerar om exekveringen av skriptet lyckades eller inte.
Om statuskoden är noll, var exekveringen av ditt skript framgångsrik. Men om värdet är något annat än noll (till exempel ett, två eller fler) indikerar det att exekveringen av skriptet inte lyckades.
För att demonstrera utgångsstatusen kör du vilket giltigt kommando som helst i ditt Bash-skal.
echo "This is a simple working command"Använd nu det här kommandot för att inspektera exitstatus för det senaste kommandot som kördes.
echo ${?}
Som du kan se är utmatningen av det här kommandot ”0” eller exitstatus för det senaste kommandot jag körde.
Denna syntax (”${?}”) kan användas i skript för att se till att kommandon exekveras korrekt.
Exitstatus kan användas i skript för att avsluta skriptet med en specifik statuskod.
Om du till exempel vill avsluta skriptet med ett fel kan du använda följande kommando i ditt skript.
exit 1På samma sätt kan du använda utgångskoden ”zero” för att ange att skriptet utfördes framgångsrikt.
exit 0För att kontrollera om statuskoden var korrekt behöver du grundläggande villkorssatser som IF-satsen.
Manipulera villkor i Bash
I vissa fall handlar exekvering av Bash-skript inte bara om att ha flera kommandon bredvid varandra: du vill ha villkorliga åtgärder.
I vissa fall kan det vara praktiskt att ha ett villkor som kontrollerar om den aktuella användaren är root-användaren (eller bara en specifik användare på ditt system).
Ett enkelt sätt att ha villkor i Bash är att använda if-satsen.
”If” är inbyggd i skalet, som en följd av detta finns manualen tillgänglig via kommandot ”help”
$ help if
Hjälpsidan beskriver syntaxen för if-kommandot med hjälp av semikolon, men vi kommer att använda den här syntaxen (som är likvärdig)
if ]then <commands>else <command>fiPraktikfall : Kontrollera om användaren är root
För att visa vad if-kommandot kan användas till kommer vi att skriva ett enkelt skript som kontrollerar om en användare är root-användare eller inte.
Som en påminnelse har root-användaren alltid UID satt till noll på alla Unix-system.
Med denna information kommer vi att kontrollera om UID är satt till noll, om så är fallet kommer vi att exekvera resten av skriptet, annars kommer vi att avsluta skriptet.
Som förklarats i andra handledningar (om användaradministration) kan du få fram det aktuella användar-ID genom att använda kommandot ”id”.
$ id -u1000Vi kommer att använda detta kommando för att kontrollera om användaren som utför skriptet är root eller inte.
Skapa ett nytt skript och lägg till shebang-linjen i det.
#!/bin/bashHelt nedanför lägger du till kommandot ”id” och lagrar resultatet i en variabel som heter ”USERID” med hjälp av kommandosubstitution.
USERID=$(id -u)Nu när ”USERID” innehåller det aktuella användar-ID, använd ett IF-statement för att kontrollera om användar-ID är noll eller inte.
Om så är fallet, skriv ett enkelt informationsmeddelande, om så inte är fallet avsluta skriptet med exitstatus 1.
if ]then echo "This is root"else exit 1fiOm du nu kör skriptet som din nuvarande användare kommer skriptet helt enkelt att avslutas med utgångsstatus ett.
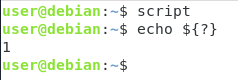
Varpå, försök nu att köra skriptet som root-användare (med kommandot sudo)
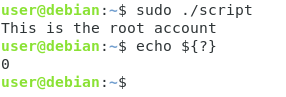
Som du kan se så visades ditt informationsmeddelande och skriptet avslutades med en felkod på noll.
Slutsats
I den här handledningen har du lärt dig om programmeringsspråket Bash och hur det kan användas för att skapa Bash-skript på ditt system.
Du har också lärt dig om exit-status och villkorliga uttalanden som är viktiga för att ha anpassad logik i dina skript.
Nu när du har mer kunskap om Bash bör du börja skriva dina egna skript för dina behov: du kan till exempel börja med att ha en handledning om att skapa arkivbackupfiler.
Om du är intresserad av Linux-systemadministration har vi en hel sektion som är dedikerad till det på webbplatsen, så se till att kolla in den!
