Amikor esti iskolába jártam, hogy programozó legyek, számos tervezési mintát tanultam: singleton, repository, factory, builder, decorator, stb. A tervezési minták bevált megoldást adnak a meglévő és visszatérő problémákra. Amit nem tanultam meg, hogy egy hasonló mechanizmus létezik egy magasabb szinten: a szoftverarchitektúra minták. Ezek az alkalmazás vagy alkalmazások általános elrendezésére szolgáló minták. Mindegyiknek vannak előnyei és hátrányai. És mindannyian konkrét problémákat kezelnek.
Layered Pattern
A rétegzett minta valószínűleg az egyik legismertebb szoftverarchitektúra-minta. Sok fejlesztő használja, anélkül, hogy igazán ismerné a nevét. A lényege, hogy a kódot “rétegekre” osztjuk, ahol minden rétegnek van egy bizonyos felelőssége, és szolgáltatást nyújt egy magasabb rétegnek.
Nincs előre meghatározott számú réteg, de ezekkel találkozhatunk a leggyakrabban:
- Prezentációs vagy felhasználói felület réteg
- alkalmazási réteg
- üzleti vagy tartományi réteg
- megmaradási vagy adatelérési réteg
- adatbázis réteg
Az elképzelés az, hogy a felhasználó valamilyen művelet végrehajtásával kezdeményez egy kódrészletet a prezentációs rétegben (pl.pl. egy gombra kattintás). A prezentációs réteg ezután meghívja az alatta lévő réteget, azaz az alkalmazási réteget. Ezután következik az üzleti réteg, és végül a perzisztencia réteg mindent az adatbázisban tárol. A magasabb rétegek tehát függnek az alacsonyabb rétegektől, és hívásokat intéznek hozzájuk.

Az alkalmazások összetettségétől függően ennek változatait láthatjuk. Egyes alkalmazások kihagyhatják az alkalmazási réteget, míg mások egy gyorsítótárazási réteget adnak hozzá. Még az is lehetséges, hogy két réteget egyesítenek egybe. Az ActiveRecord minta például egyesíti az üzleti és a perszisztencia réteget.
Rétegek felelőssége
Amint említettük, minden rétegnek megvan a maga felelőssége. A prezentációs réteg tartalmazza az alkalmazás grafikai tervezését, valamint a felhasználói interakciót kezelő kódot. Ebben a rétegben nem szabad olyan logikát elhelyezni, amely nem a felhasználói felületre jellemző.
Az üzleti rétegbe kerülnek a megoldandó üzleti problémára jellemző modellek és logika.
A prezentációs réteg és az üzleti réteg között helyezkedik el az alkalmazási réteg. Egyrészt absztrakciót biztosít, hogy a prezentációs rétegnek ne kelljen ismernie az üzleti réteget. Elméletileg megváltoztathatja a prezentációs réteg technológiai stackjét anélkül, hogy bármi mást megváltoztatna az alkalmazásban (pl. WinFormsról WPF-re váltana). Másrészt az alkalmazási réteg helyet biztosít bizonyos koordinációs logikák elhelyezésére, amelyek nem illeszkednek az üzleti vagy a prezentációs rétegbe.
Végül a perzisztencia réteg tartalmazza az adatbázis réteg eléréséhez szükséges kódot. Az adatbázis-réteg a mögöttes adatbázis-technológia (pl. SQL Server, MongoDB). A perzisztencia réteg az adatbázis manipulálására szolgáló kódkészlet: SQL utasítások, kapcsolati adatok stb.
Előnyei
- A legtöbb fejlesztő ismeri ezt a mintát.
- Egyszerű módot biztosít egy jól szervezett és tesztelhető alkalmazás megírására.
Hátrányok
- Hajlamos monolitikus alkalmazásokhoz vezetni, amelyeket utólag nehéz felosztani.
- A fejlesztők gyakran azon kapják magukat, hogy rengeteg kódot írnak a különböző rétegek átjárásához, anélkül, hogy ezekben a rétegekben bármilyen értéket hozzáadnának. Ha csak egy egyszerű CRUD-alkalmazást írsz, a réteges minta túlzás lehet számodra.
Ideális
- Szokásos line-of-business alkalmazásokhoz, amelyek nem csak CRUD műveleteket végeznek
Mikrokernel
A mikrokernel-minta, vagy plug-in-minta akkor hasznos, ha az alkalmazásnak van egy alapvető feladatköre és oldalt cserélhető részek gyűjteménye. A mikrokernel biztosítja a belépési pontot és az alkalmazás általános áramlását, anélkül, hogy igazán tudnánk, mit csinálnak a különböző beépülő modulok.
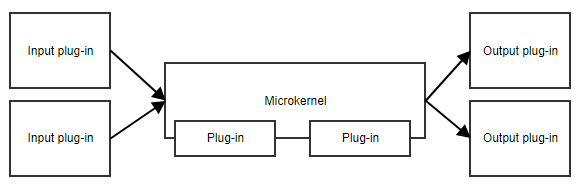
Egy példa erre egy feladatütemező. A mikrokernel tartalmazhatja a feladatok ütemezésének és kiváltásának teljes logikáját, míg a beépülő modulok konkrét feladatokat tartalmaznak. Amíg a beépülő modulok egy előre meghatározott API-t követnek, a mikrokernel anélkül indíthatja el őket, hogy ismernie kellene a megvalósítás részleteit.
Egy másik példa egy munkafolyamat. Egy munkafolyamat megvalósítása olyan fogalmakat tartalmaz, mint a különböző lépések sorrendje, a lépések eredményeinek kiértékelése, a következő lépés eldöntése stb. A lépések konkrét megvalósítása kevésbé fontos a munkafolyamat magkódjához képest.
Előnyök
- Ez a minta nagy rugalmasságot és bővíthetőséget biztosít.
- Egyes megvalósítások lehetővé teszik a bővítmények hozzáadását az alkalmazás futása közben.
- A mikromagot és a bővítményeket külön csapatok fejleszthetik.
Hátrányok
- Nehéz lehet eldönteni, hogy mi tartozik a mikromagba és mi nem.
- Az előre definiált API nem biztos, hogy jól illeszkedik a jövőbeli bővítményekhez.
Ideális
- Azokhoz az alkalmazásokhoz, amelyek különböző forrásokból veszik az adatokat, átalakítják azokat, és különböző célállomásokra írják
- A munkafolyamat-alkalmazásokhoz
- A feladat- és munkaszervezési alkalmazásokhoz
CQRS
A CQRS a Command and Query Responsibility Segregation rövidítése. Ennek a mintának a központi koncepciója az, hogy egy alkalmazásnak vannak olvasási és írási műveletei, amelyeket teljesen el kell választani egymástól. Ez azt is jelenti, hogy az írási műveletekhez (parancsok) használt modell eltér az olvasási modellektől (lekérdezések). Továbbá az adatokat különböző helyeken fogják tárolni. Egy relációs adatbázisban ez azt jelenti, hogy lesznek táblák a parancsmodellhez és táblák az olvasási modellhez. Egyes megvalósítások még a különböző modelleket is teljesen különböző adatbázisokban tárolják, például az SQL Server a parancsmodellhez és a MongoDB az olvasási modellhez.
Ezt a mintát gyakran kombinálják eseményforrással, amivel alább foglalkozunk.
Hogyan működik ez pontosan? Amikor a felhasználó végrehajt egy műveletet, az alkalmazás parancsot küld a parancsszolgáltatásnak. A parancsszolgáltatás lekérdezi a szükséges adatokat a parancsadatbázisból, elvégzi a szükséges manipulációkat, és visszatárolja azokat az adatbázisba. Ezután értesíti az olvasási szolgáltatást, hogy az olvasási modell frissülhessen. Ez az áramlás alább látható.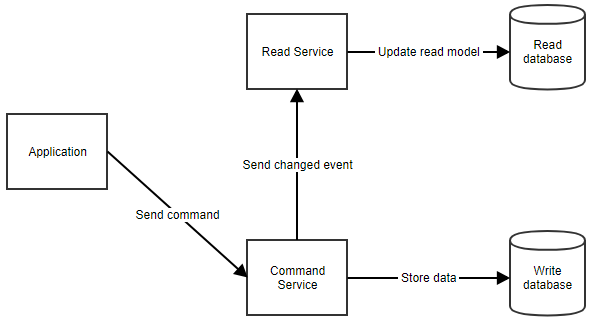
Amikor az alkalmazásnak adatokat kell megjelenítenie a felhasználónak, az olvasási modellt az olvasási szolgáltatás hívásával kérheti le, ahogy az alább látható.
Előnyök
- A parancsmodellek az üzleti logikára és az érvényesítésre összpontosíthatnak, míg az olvasási modellek az adott forgatókönyvekre szabhatók.
- Elkerülhetők a bonyolult lekérdezések (pl. joins az SQL-ben), ami az olvasást hatékonyabbá teszi.
Hátrányok
- A parancs- és az olvasási modellek szinkronban tartása bonyolulttá válhat.
Ideális
- Magas olvasási mennyiséget váró alkalmazásokhoz
- Bonyolult tartományokkal rendelkező alkalmazásokhoz
Event Sourcing
Mint fentebb említettem, a CQRS gyakran kéz a kézben jár az eseményforrással. Ez egy olyan minta, ahol nem a modell aktuális állapotát tároljuk az adatbázisban, hanem a modellel történt eseményeket. Tehát amikor egy ügyfél neve megváltozik, nem a “Név” oszlopban tárolja az értéket. Egy “NameChanged” eseményt fogsz tárolni az új értékkel (és esetleg a régivel is).
Amikor egy modellt le kell hívnod, az összes tárolt eseményt lekérdezed és újra alkalmazod egy új objektumra. Ezt nevezzük egy objektum rehidratálásának.
A valós életben az eseményforrás-kezelés analógiája a könyvelés. Amikor hozzáadunk egy kiadást, nem változtatjuk meg a végösszeg értékét. A könyvelésben egy új sort adunk hozzá az elvégzendő művelettel. Ha hiba történt, egyszerűen hozzáad egy új sort. Hogy megkönnyítse az életét, minden egyes sor hozzáadásakor kiszámíthatja a végösszeget. Ezt a végösszeget tekinthetjük a beolvasott modellnek. Az alábbi példa érthetőbbé teszi a dolgot:

Láthatjuk, hogy hibát követtünk el a 201805-ös számla hozzáadásakor. Ahelyett, hogy megváltoztattuk volna a sort, két új sort adtunk hozzá: először egyet a hibás sor törlésére, majd egy új, helyes sort. Így működik az eseményforrás-kezelés. Soha nem távolítjuk el az eseményeket, mert azok tagadhatatlanul megtörténtek a múltban. A helyzetek kijavításához új eseményeket adunk hozzá.
Azt is figyeljük meg, hogy van egy cellánk az összértékkel. Ez egyszerűen a fenti cellákban lévő összes érték összege. Az Excelben automatikusan frissül, így mondhatni szinkronizálódik a többi cellával. Ez az olvasási modell, amely egyszerű nézetet biztosít a felhasználó számára.
Az eseményforrás-alapúságot gyakran kombinálják a CQRS-sel, mert egy objektum rehidratálása hatással lehet a teljesítményre, különösen, ha a példányhoz sok esemény tartozik. Egy gyors olvasási modell jelentősen javíthatja az alkalmazás válaszidejét.
Előnyök
- Ez a szoftverarchitektúra-mintázat azonnal képes ellenőrzési naplót biztosítani. Minden esemény az adatok egy adott időpontban történő manipulációját jelenti.
Hátrányok
- Ez némi fegyelmet igényel, mert nem lehet a rossz adatokat egy egyszerű szerkesztéssel kijavítani az adatbázisban.
- Egy esemény szerkezetének megváltoztatása nem triviális feladat. Ha például hozzáadsz egy tulajdonságot, az adatbázisban még mindig vannak olyan események, amelyek nem tartalmazzák ezt az adatot. A kódodnak ezt a hiányzó adatot kegyesen kell kezelnie.
Ideális olyan alkalmazásokhoz, amelyek
- Azokat az eseményeket külső rendszerekben kell közzétenni
- A CQRS segítségével épülnek
- A komplex tartományok
- Az adatok változásainak ellenőrzési naplójára van szükségük
Mikroszolgáltatások
Ha az alkalmazást mikroszolgáltatások halmazaként írja meg, valójában több alkalmazást írsz, amelyek együtt fognak működni. Minden egyes mikroszolgáltatásnak megvan a maga különálló felelőssége, és a csapatok a többi mikroszolgáltatástól függetlenül fejleszthetik őket. Az egyetlen függőség közöttük a kommunikáció. Mivel a mikroszolgáltatások kommunikálnak egymással, gondoskodnia kell arról, hogy a közöttük küldött üzenetek visszafelé kompatibilisek maradjanak. Ez némi koordinációt igényel, különösen akkor, ha különböző csapatok felelősek a különböző mikroszolgáltatásokért.
Egy ábra megmagyarázhatja.
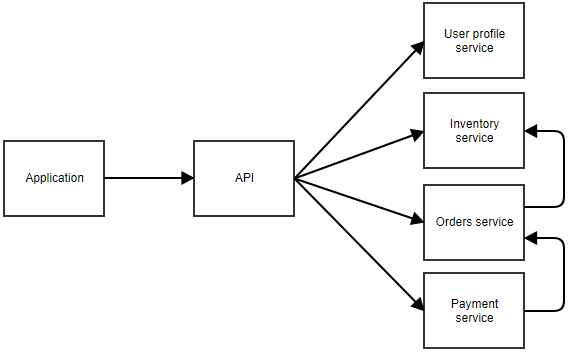 A fenti ábrán az alkalmazás egy központi API-t hív, amely továbbítja a hívást a megfelelő mikroszolgáltatáshoz. Ebben a példában különálló szolgáltatások vannak a felhasználói profil, a készlet, a megrendelések és a fizetés számára. Elképzelhető, hogy ez egy olyan alkalmazás, ahol a felhasználó rendelhet valamit. A különálló mikroszolgáltatások egymást is hívhatják. Például a fizetési szolgáltatás értesítheti a megrendelések szolgáltatást, ha egy fizetés sikeres. A megrendelések szolgáltatás ezután meghívhatja a leltárszolgáltatást a készlet módosítására.
A fenti ábrán az alkalmazás egy központi API-t hív, amely továbbítja a hívást a megfelelő mikroszolgáltatáshoz. Ebben a példában különálló szolgáltatások vannak a felhasználói profil, a készlet, a megrendelések és a fizetés számára. Elképzelhető, hogy ez egy olyan alkalmazás, ahol a felhasználó rendelhet valamit. A különálló mikroszolgáltatások egymást is hívhatják. Például a fizetési szolgáltatás értesítheti a megrendelések szolgáltatást, ha egy fizetés sikeres. A megrendelések szolgáltatás ezután meghívhatja a leltárszolgáltatást a készlet módosítására.
Nincs egyértelmű szabály arra, hogy mekkora lehet egy mikroszolgáltatás. Az előző példában a felhasználói profil szolgáltatás olyan adatokért lehet felelős, mint a felhasználó felhasználóneve és jelszava, de a lakcím, avatárkép, kedvencek stb. is. Az is egy lehetőség lehet, hogy mindezeket a feladatokat még kisebb mikroszolgáltatásokra osszuk fel.
előnyök
- Minden mikroszolgáltatást külön-külön írhatunk, karbantarthatunk és telepíthetünk.
- A mikroszolgáltatási architektúra könnyebben skálázható, mivel csak azokat a mikroszolgáltatásokat skálázhatjuk, amelyeket skálázni kell. Nincs szükség az alkalmazás ritkábban használt részeinek skálázására.
- Egyszerűbb az alkalmazás egyes darabjait újraírni, mivel azok kisebbek és kevésbé kapcsolódnak más részekhez.
Hátrányok
- Azzal ellentétben, amit várnánk, valójában könnyebb először egy jól strukturált monolitot írni, és később mikroszolgáltatásokra bontani. A mikroszolgáltatásoknál rengeteg extra aggály kerül a képbe: kommunikáció, koordináció, visszafelé kompatibilitás, naplózás stb. Azok a csapatok, amelyek nem rendelkeznek a jól strukturált monolitok megírásához szükséges készséggel, valószínűleg nehezen fognak jó mikroszolgáltatásokat írni.
- A felhasználó egyetlen művelete több mikroszolgáltatáson is áthaladhat. Több hibapont van, és ha valami elromlik, több időbe telhet a probléma behatárolása.
Ideal for:
- Alkalmazások, ahol bizonyos részeket intenzíven használnak, és skálázásra szorulnak
- Szolgáltatások, amelyek több más alkalmazás számára nyújtanak funkciókat
- Alkalmazások, amelyek nagyon összetetté válnának, ha egyetlen monolitba egyesítenék őket
- Alkalmazások, ahol egyértelműen körülhatárolt kontextusok határozhatók meg
Kombinálni
Már több szoftverarchitektúra-mintát ismertettem, valamint azok előnyeit és hátrányait. De az itt kifejtetteken kívül még több minta létezik. Az sem ritka, hogy több ilyen mintát kombinálunk. Nem mindig zárják ki egymást. Lehet például több mikroszolgáltatásunk, és némelyikük használhatja a rétegzett mintát, míg mások a CQRS-t és az eseményforrás-kezelést.
A fontos dolog, amit nem szabad elfelejtenünk, hogy nem létezik egyetlen megoldás, amely mindenhol működik. Amikor feltesszük a kérdést, hogy melyik mintát használjuk egy alkalmazáshoz, az ősrégi válasz még mindig érvényes: “attól függ”. Mérlegelni kell a megoldás előnyeit és hátrányait, és megalapozott döntést kell hozni.