Când am urmat cursurile serale pentru a deveni programator, am învățat câteva modele de proiectare: singleton, repository, factory, builder, decorator, etc. Modelele de proiectare ne oferă o soluție dovedită la probleme existente și recurente. Ceea ce nu am învățat a fost că un mecanism similar există la un nivel superior: modelele de arhitectură software. Acestea sunt tipare pentru aspectul general al aplicației sau aplicațiilor dumneavoastră. Toate acestea au avantaje și dezavantaje. Și toate abordează probleme specifice.
Planul stratificat
Planul stratificat este probabil unul dintre cele mai cunoscute modele de arhitectură software. Mulți dezvoltatori îl folosesc, fără a-i cunoaște cu adevărat numele. Ideea este de a vă împărți codul în „straturi”, în care fiecare strat are o anumită responsabilitate și furnizează un serviciu unui strat superior.
Nu există un număr predefinit de straturi, dar acestea sunt cele pe care le vedeți cel mai des:
- Capa de prezentare sau de interfață utilizator
- Capa de aplicație
- Capa de afaceri sau de domeniu
- Capa de persistență sau de acces la date
- Capa de bază de date
Ideea este că utilizatorul inițiază o bucată de cod în stratul de prezentare prin efectuarea unei anumite acțiuni (de ex.ex. apăsarea unui buton). Stratul de prezentare apelează apoi stratul subiacent, adică stratul de aplicație. Apoi trecem la stratul de afaceri și, în cele din urmă, stratul de persistență stochează totul în baza de date. Așadar, straturile superioare depind de straturile inferioare și fac apeluri către acestea.

Vă veți vedea variații ale acestui lucru, în funcție de complexitatea aplicațiilor. Unele aplicații pot omite stratul de aplicații, în timp ce altele adaugă un strat de cache. Este chiar posibil să se fuzioneze două straturi într-unul singur. De exemplu, modelul ActiveRecord combină straturile de afaceri și de persistență.
Responsabilitatea straturilor
După cum am menționat, fiecare strat are propria sa responsabilitate. Stratul de prezentare conține proiectarea grafică a aplicației, precum și orice cod pentru a gestiona interacțiunea cu utilizatorul. Nu ar trebui să adăugați logică care nu este specifică interfeței cu utilizatorul în acest strat.
Stratul de afaceri este cel în care puneți modelele și logica specifică problemei de afaceri pe care încercați să o rezolvați.
Stratul aplicației se află între stratul de prezentare și stratul de afaceri. Pe de o parte, acesta oferă o abstractizare astfel încât stratul de prezentare nu trebuie să cunoască stratul de afaceri. În teorie, ați putea schimba stiva tehnologică a stratului de prezentare fără a schimba nimic altceva în aplicație (de exemplu, trecerea de la WinForms la WPF). Pe de altă parte, stratul de aplicație oferă un loc pentru a plasa anumite logici de coordonare care nu se potrivesc în stratul de afaceri sau în stratul de prezentare.
În cele din urmă, stratul de persistență conține codul de accesare a stratului de bază de date. Stratul bazei de date reprezintă tehnologia de bază de date care stă la baza acestuia (de exemplu, SQL Server, MongoDB). Stratul de persistență este setul de cod pentru a manipula baza de date: Instrucțiuni SQL, detalii de conectare, etc.
Avantaje
- Majoritatea dezvoltatorilor sunt familiarizați cu acest model.
- Aprovizionează o modalitate ușoară de a scrie o aplicație bine organizată și testabilă.
Dezavantaje
- Tinde să ducă la aplicații monolitice care sunt greu de divizat ulterior.
- Dezvoltatorii se trezesc adesea că scriu o mulțime de cod pentru a trece prin diferitele straturi, fără a adăuga nicio valoare în aceste straturi. Dacă tot ceea ce faceți este să scrieți o aplicație CRUD simplă, modelul stratificat ar putea fi exagerat pentru dumneavoastră.
Ideal pentru
- Aplicații line-of-business standard care fac mai mult decât simple operații CRUD
Microkernel
Patronul microkernel, sau modelul plug-in, este util atunci când aplicația dumneavoastră are un set de responsabilități de bază și o colecție de părți interschimbabile în lateral. Microkernelul va furniza punctul de intrare și fluxul general al aplicației, fără a ști cu adevărat ce fac diferitele plug-in-uri.
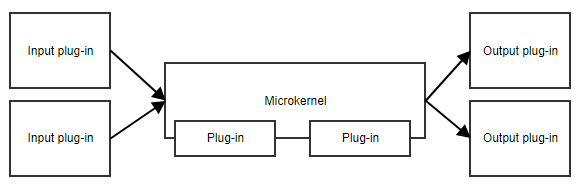
Un exemplu este un planificator de sarcini. Microkernelul ar putea conține toată logica pentru programarea și declanșarea sarcinilor, în timp ce plug-in-urile conțin sarcini specifice. Atâta timp cât plug-in-urile aderă la o API predefinită, microkernelul le poate declanșa fără a fi nevoie să cunoască detaliile de implementare.
Un alt exemplu este un flux de lucru. Implementarea unui flux de lucru conține concepte cum ar fi ordinea diferiților pași, evaluarea rezultatelor pașilor, decizia care este următorul pas, etc. Implementarea specifică a pașilor este mai puțin importantă pentru codul de bază al fluxului de lucru.
Avantaje
- Acest model oferă o mare flexibilitate și extensibilitate.
- Câteva implementări permit adăugarea de plug-in-uri în timp ce aplicația rulează.
- Microkernelul și plug-in-urile pot fi dezvoltate de echipe separate.
Dezavantaje
- Poate fi dificil să se decidă ce aparține microkernelului și ce nu.
- API-ul predefinit ar putea să nu se potrivească bine pentru viitoarele plug-in-uri.
Ideal pentru
- Aplicații care preiau date din diferite surse, transformă aceste date și le scriu către diferite destinații
- Aplicații de flux de lucru
- Aplicații de programare a sarcinilor și a lucrărilor
CQRS
CQRS este un acronim pentru Command and Query Responsibility Segregation (segregare a responsabilității de comandă și interogare). Conceptul central al acestui model este că o aplicație are operații de citire și operații de scriere care trebuie să fie total separate. Acest lucru înseamnă, de asemenea, că modelul utilizat pentru operațiunile de scriere (comenzi) va fi diferit de modelele de citire (interogări). În plus, datele vor fi stocate în locații diferite. Într-o bază de date relațională, acest lucru înseamnă că vor exista tabele pentru modelul de comandă și tabele pentru modelul de citire. Unele implementări chiar stochează diferitele modele în baze de date total diferite, de exemplu SQL Server pentru modelul de comandă și MongoDB pentru modelul de citire.
Acest model este adesea combinat cu event sourcing, pe care îl vom aborda mai jos.
Cum funcționează exact? Atunci când un utilizator efectuează o acțiune, aplicația trimite o comandă către serviciul de comandă. Serviciul de comenzi recuperează toate datele de care are nevoie din baza de date de comenzi, face manipulările necesare și le stochează înapoi în baza de date. Apoi notifică serviciul de citire, astfel încât modelul de citire să poată fi actualizat. Acest flux poate fi văzut mai jos.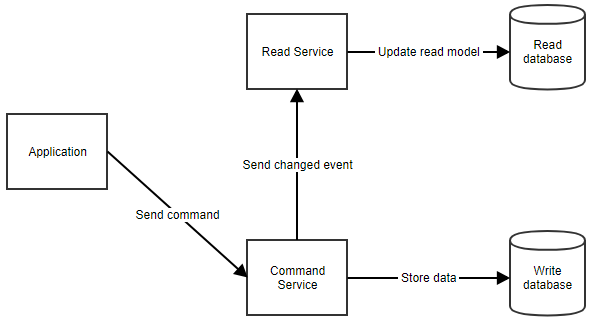
Când aplicația trebuie să afișeze date utilizatorului, aceasta poate prelua modelul de citire prin apelarea serviciului de citire, așa cum se arată mai jos.
Avantaje
- Modelurile de comandă se pot concentra pe logica de afaceri și validare, în timp ce modelele de citire pot fi adaptate la scenarii specifice.
- Puteți evita interogările complexe (de ex. îmbinări în SQL), ceea ce face ca citirile să fie mai performante.
Dezvantaje
- Menținerea sincronizării între modelele de comandă și cele de citire poate deveni complexă.
Ideal pentru
- Aplicații care se așteaptă la un număr mare de citiri
- Aplicații cu domenii complexe
Event Sourcing
După cum am menționat mai sus, CQRS merge adesea mână în mână cu event sourcing. Acesta este un model în care nu stocați starea curentă a modelului în baza de date, ci mai degrabă evenimentele care s-au întâmplat cu modelul. Astfel, atunci când numele unui client se schimbă, nu veți stoca valoarea într-o coloană „Name”. Veți stoca un eveniment „NameChanged” cu noua valoare (și, eventual, și pe cea veche).
Când trebuie să recuperați un model, recuperați toate evenimentele stocate și le aplicați din nou pe un nou obiect. Noi numim acest lucru rehidratare a unui obiect.
O analogie din viața reală a sursei de evenimente este contabilitatea. Atunci când adăugați o cheltuială, nu schimbați valoarea totală. În contabilitate, se adaugă o nouă linie cu operațiunea care urmează să fie efectuată. Dacă s-a făcut o eroare, pur și simplu se adaugă o nouă linie. Pentru a vă face viața mai ușoară, ați putea calcula totalul de fiecare dată când adăugați o linie. Acest total poate fi considerat ca fiind modelul de citire. Exemplul de mai jos ar trebui să fie mai clar.

Vezi că am făcut o eroare atunci când am adăugat Factura 201805. În loc să modificăm linia, am adăugat două linii noi: mai întâi, una pentru a anula linia greșită, apoi o linie nouă și corectă. Acesta este modul în care funcționează aprovizionarea cu evenimente. Nu eliminați niciodată evenimentele, deoarece acestea s-au întâmplat în mod incontestabil în trecut. Pentru a corecta situațiile, adăugăm noi evenimente.
De asemenea, observați cum avem o celulă cu valoarea totală. Aceasta este pur și simplu o sumă a tuturor valorilor din celulele de mai sus. În Excel, se actualizează automat, așa că se poate spune că se sincronizează cu celelalte celule. Este modelul de citire, oferind o vizualizare ușoară pentru utilizator.
Sursa de evenimente este adesea combinată cu CQRS deoarece rehidratarea unui obiect poate avea un impact asupra performanței, în special atunci când există o mulțime de evenimente pentru instanță. Un model de citire rapidă poate îmbunătăți semnificativ timpul de răspuns al aplicației.
Avantaje
- Acest model de arhitectură software poate furniza un jurnal de audit din start. Fiecare eveniment reprezintă o manipulare a datelor la un anumit moment.
Dezavantaje
- Este nevoie de o anumită disciplină, deoarece nu puteți repara datele greșite cu o simplă editare în baza de date.
- Nu este o sarcină banală să modificați structura unui eveniment. De exemplu, dacă adăugați o proprietate, baza de date conține în continuare evenimente fără acele date. Codul dvs. va trebui să se ocupe cu grație de aceste date lipsă.
Ideal pentru aplicațiile care
- trebuie să publice evenimente către sisteme externe
- Vor fi construite cu CQRS
- Au complexitate. domenii
- Au nevoie de un jurnal de audit al modificărilor aduse datelor
Microservicii
Când vă scrieți aplicația ca un set de microservicii, scrieți, de fapt, mai multe aplicații care vor funcționa împreună. Fiecare microserviciu are propria responsabilitate distinctă și echipele le pot dezvolta independent de alte microservicii. Singura dependență dintre ele este comunicarea. Pe măsură ce microserviciile comunică între ele, va trebui să vă asigurați că mesajele trimise între ele rămân compatibile cu versiunile anterioare. Acest lucru necesită o anumită coordonare, în special atunci când echipe diferite sunt responsabile pentru microservicii diferite.
O diagramă poate explica.
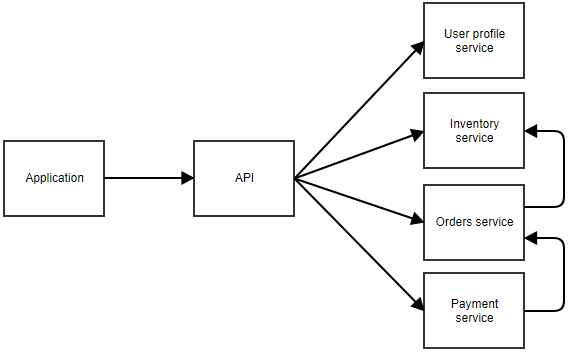 În diagrama de mai sus, aplicația apelează o API centrală care redirecționează apelul către microserviciul corect. În acest exemplu, există servicii separate pentru profilul utilizatorului, inventar, comenzi și plată. Vă puteți imagina că aceasta este o aplicație în care utilizatorul poate comanda ceva. Microserviciile separate se pot apela și între ele. De exemplu, serviciul de plată poate notifica serviciul de comenzi atunci când o plată reușește. Serviciul de comenzi ar putea apoi să apeleze serviciul de inventar pentru a ajusta stocul.
În diagrama de mai sus, aplicația apelează o API centrală care redirecționează apelul către microserviciul corect. În acest exemplu, există servicii separate pentru profilul utilizatorului, inventar, comenzi și plată. Vă puteți imagina că aceasta este o aplicație în care utilizatorul poate comanda ceva. Microserviciile separate se pot apela și între ele. De exemplu, serviciul de plată poate notifica serviciul de comenzi atunci când o plată reușește. Serviciul de comenzi ar putea apoi să apeleze serviciul de inventar pentru a ajusta stocul.
Nu există o regulă clară cu privire la cât de mare poate fi un microserviciu. În exemplul anterior, serviciul de profil de utilizator poate fi responsabil pentru date precum numele de utilizator și parola unui utilizator, dar și adresa de domiciliu, imaginea avatarului, favoritele etc. De asemenea, ar putea fi o opțiune să împărțiți toate aceste responsabilități în microservicii și mai mici.
Avantaje
- Puteți scrie, întreține și implementa fiecare microserviciu separat.
- O arhitectură de microservicii ar trebui să fie mai ușor de scalat, deoarece puteți scala doar microserviciile care trebuie să fie scalate. Nu este nevoie să scalați piesele mai puțin utilizate ale aplicației.
- Este mai ușor să rescrieți piese ale aplicației, deoarece acestea sunt mai mici și mai puțin cuplate cu alte părți.
Dezavantaje
- Contrar a ceea ce v-ați putea aștepta, este de fapt mai ușor să scrieți un monolit bine structurat la început și să îl împărțiți în microservicii mai târziu. În cazul microserviciilor, intră în joc o mulțime de preocupări suplimentare: comunicare, coordonare, compatibilitate retroactivă, logare etc. Echipele cărora le lipsește abilitatea necesară pentru a scrie un monolit bine structurat vor avea probabil dificultăți în a scrie un set bun de microservicii.
- O singură acțiune a unui utilizator poate trece prin mai multe microservicii. Există mai multe puncte de eșec, iar atunci când ceva nu merge bine, poate dura mai mult timp pentru a identifica problema.
Ideal pentru:
- Aplicații în care anumite părți vor fi folosite intensiv și trebuie să fie scalate
- Servicii care oferă funcționalitate pentru mai multe alte aplicații
- Aplicații care ar deveni foarte complexe dacă ar fi combinate într-un monolit
- Aplicații în care pot fi definite contexte delimitate clar
Combinați
Am explicat mai multe modele de arhitectură software, precum și avantajele și dezavantajele acestora. Dar există mai multe tipare decât cele pe care le-am expus aici. De asemenea, nu este neobișnuit să se combine mai multe dintre aceste tipare. Ele nu se exclud întotdeauna reciproc. De exemplu, ați putea avea mai multe microservicii și unele dintre ele să folosească modelul stratificat, în timp ce altele folosesc CQRS și event sourcing.
Ceea ce este important de reținut este că nu există o singură soluție care funcționează peste tot. Când ne punem întrebarea ce model să folosim pentru o aplicație, vechiul răspuns se aplică în continuare: „depinde”. Ar trebui să cântăriți avantajele și dezavantajele unei soluții și să luați o decizie bine informată.
.